

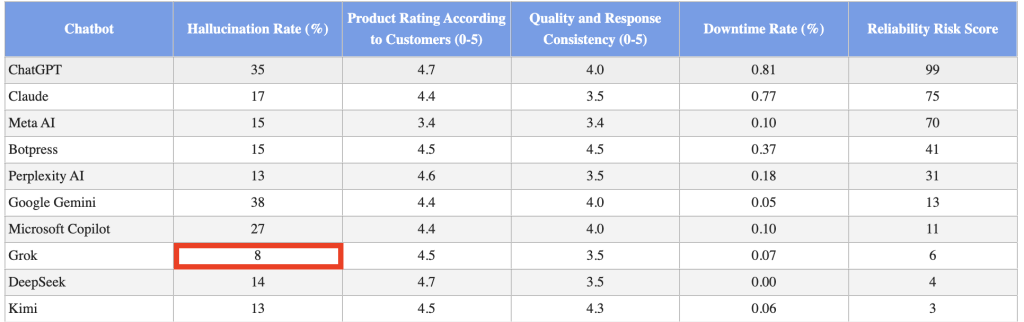
相比之下,市场领导者 ChatGPT 的幻觉率最高,达到 35%,仅次于 Google 的 Gemini,后者的幻觉率高达 38%。
尽管人工智能模型的市场知名度较低,但调查结果凸显了 Grok 的事实实力。
Grok 的幻觉指标最高
的研究对聊天机器人的幻觉率、客户评级、响应一致性和停机率进行了评估。然后,聊天机器人被分配了从 0 到 99 的可靠性风险评分,分数越高表明问题越大。
Grok 达到了 8%幻觉率、4.5 的客户评级、3.5 的一致性和 0.07% 的停机时间,总体风险评分仅为 6。DeepSeek 紧随其后,幻觉率为 14%,停机时间为零,风险评分为 4。ChatGPT 的高幻觉和停机率使其风险评分最高,为 99,其次是 Claude 和 Meta AI,可靠性风险评分分别为 75 和 70。分别。
为什么低幻觉很重要
雷鲁姆首席产品官 Razvan-Lucian Haiduc 分享了他对该研究结果的看法。– 大约 65% 的美国公司现在在日常工作中使用人工智能聊天机器人,近 45% 的员工承认他们曾使用这些工具共享敏感的公司信息。这些数字很好地表明了聊天机器人在日常工作中的重要性。
– 对人工智能工具的依赖可能会进一步增加,因此公司应根据聊天机器人的可靠性和适合其特定业务需求的程度来选择聊天机器人。每个人都使用的聊天机器人不一定最适合您的行业或为您的任务提供准确的答案。”
在某种程度上,该研究揭示了人工智能聊天机器人的受欢迎程度和性能之间的显着差距,Grok 的低幻觉率使其成为精度关键型应用程序的有力选择。尽管事实上 Grok 的用户使用率并不高,至少与 ChatGPT 等更主流的人工智能应用程序相比是这样。
![]()
西蒙是一位经验丰富的汽车记者,对电动汽车和清洁能源充满热情。他对埃隆·马斯克设想的世界着迷,希望有一天能够到达火星(至少作为游客)。如需故事或提示,甚至只是简单的打个招呼,请向他的电子邮件发送消息,simon@teslarati.com或者他在 X 上的手柄,@ResidentSponge。
![]()


