

人工智能的记忆危机
作者:Alex Reisner
编者注:本作品是人工智能看门狗,大西洋月刊– 对生成型人工智能行业正在进行的调查。
氧周二,斯坦福大学和耶鲁大学的研究人员透露人工智能公司宁愿隐藏的东西。四种流行的大型语言模型——OpenAI 的 GPT、Anthropic 的 Claude、Google 的 Gemini 和 xAI 的 Grok——已经存储了它们接受过训练的一些书籍的大部分内容,并且可以从这些书籍中复制长摘录。
事实上,当研究人员有策略地提示时,克劳德交付了近乎完整的文本哈利·波特与魔法石,了不起的盖茨比,1984年, 和弗兰肯斯坦,除了书中的数千字,包括饥饿游戏和麦田里的守望者。其他三个模型也复制了不同数量的这些书籍。测试了十三本书。
这种现象被称为“记忆”,而人工智能公司长期以来一直否认这种现象大规模发生。在 2023 年致美国版权局的信中,OpenAI说“模型不会存储它们所学到的信息的副本。”Google 也类似告诉版权局表示“模型本身不存在训练数据的副本,无论是文本、图像还是其他格式。”人择,元,微软等人也提出了类似的主张。(本文提到的人工智能公司都没有同意我的采访请求。)
斯坦福大学的研究证明,是人工智能模型中存在这样的副本,这只是多项研究中最新的一项。在我自己的调查中,我发现基于图像的模型可以重现他们接受训练的一些艺术和照片。对于人工智能公司来说,这可能是一项巨大的法律责任,可能会导致该行业因版权侵权判决而损失数十亿美元,并导致产品退出市场。这也与人工智能行业对其技术如何运作的基本解释相矛盾。一个
我经常被解释就隐喻而言;科技公司喜欢说他们的产品学习,例如,法学硕士在没有明确被告知英语语法规则的情况下就已经发展了对英语写作的理解。这项新研究以及过去两年的其他几项研究破坏了这个比喻。人工智能不像人类大脑那样吸收信息。相反,它存储信息并访问它。
事实上,许多人工智能开发人员在谈论这些模型时使用了技术上更准确的术语:有损压缩。它也开始在行业之外获得关注。德国一家法院最近援引了这句话OpenAI 被判败诉音乐许可组织 GEMA 提起的案件。GEMA 表明 ChatGPT 可以输出歌词的近似模仿。法官将该模型与 MP3 和 JPEG 文件进行了比较,后者将音乐和照片存储在比原始未压缩原件更小的文件中。例如,当您将高质量照片存储为 JPEG 时,结果会是质量稍差的照片,在某些情况下还会添加模糊或视觉伪影。有损压缩算法仍然存储照片,但它是一个近似值而不是精确的文件。它被称为有损的压缩,因为部分数据丢失。从技术角度来看,这种压缩过程很像人工智能模型内部发生的情况,正如几家人工智能公司和大学的研究人员在过去几个月向我解释的那样。
它们摄取文本和图像,并输出文本和图像近似这些输入。
但这个简单的描述对人工智能公司来说不如学习隐喻有用,学习隐喻被用来声称称为人工智能的统计算法最终会做出新的科学发现,经历无限的改进,并递归地训练自己,可能会导致——智力爆炸……整个行业都押在一个不稳定的隐喻上。时间
问题变得清晰起来如果我们看看人工智能图像生成器。2022 年 9 月,Stability AI 联合创始人兼时任首席执行官 Emad Mostaque解释了在播客采访中,稳定扩散(稳定的形象模型)是如何构建的。“我们拍摄了 100,000 GB 的图像,并将其压缩为 2 GB 的文件,该文件可以重新创建任何这些图像以及这些图像的迭代,”他说。
我在报道本文时采访的众多专家之一是一位独立的人工智能研究人员,他研究了稳定扩散重现其训练图像的能力。(我同意让研究人员保持匿名,因为他们担心主要人工智能公司的影响。)上面是这种能力的一个例子:左边是网络原文——电视节目的宣传图片加芬克尔和奥茨– 右侧是稳定扩散在提示图像在网络上显示的标题时生成的版本,其中包括一些 HTML 代码: – IFC 取消加芬克尔和奥茨使用这种简单的技术,研究人员向我展示了如何生成稳定扩散训练集中已知的几十张图像的近乎精确的副本,其中大多数图像都包含看起来像有损压缩的视觉残留物,这种小故障、模糊的效果你可能会不时在自己的照片中注意到。

资料来源:卡拉·奥尔蒂斯
Karla Ortiz 的原创艺术作品(我带来的死亡,2016,石墨)

资料来源:美国加利福尼亚州北区地方法院
Stability 的 Reimagine XL 产品的输出(基于 Stable Diffusion XL)
上面是另一对来自针对 Stability AI 和其他公司的诉讼的图像。左边是 Karla Ortiz 的原创作品,右边是 Stable Diffusion 的变体。这里,图像与原始图像有点远。一些元素已经改变。该算法似乎不是在像素级进行压缩,而是从多个图像中复制和操作对象,同时保持一定程度的视觉连续性。
正如公司所解释的那样,人工智能算法从训练数据中提取“概念”并学习创作原创作品。但右边的图像不仅仅是概念的产物。它不是一个通用图像,例如“天使与鸟”。很难确定为什么任何 AI 模型会在图像中做出任何特定标记,但我们可以合理地假设稳定扩散可以渲染右侧图像,部分原因是它存储了左侧图像的视觉元素。它不是物理剪切和粘贴意义上的拼贴,但它也不是学习从人类的意义上来说,这个词意味着。模型没有感官或有意识的经验来做出自己的审美判断。
G谷歌有书面的 法学硕士存储的不是训练数据的副本,而是“人类语言的模式”。这从表面上看是正确的,但一旦深入研究就会产生误导。正如已被广泛有记录的,当一家公司使用一本书来开发人工智能模型时,它会将书中的文本拆分为标记或单词片段。例如,短语你好,我的朋友可能由令牌表示他,你好,我的,星期五, 和结束。有些标记是实际的单词;有些标记是实际的单词。有些只是字母、空格和标点符号的组合。该模型存储这些标记以及它们在书中出现的上下文。由此产生的 LLM 本质上是一个巨大的上下文数据库和接下来最有可能出现的标记。
该模型可以可视化为地图。这是一个示例,其中包含来自 Meta 的 Llama-3.1-70B 的实际最有可能的令牌:
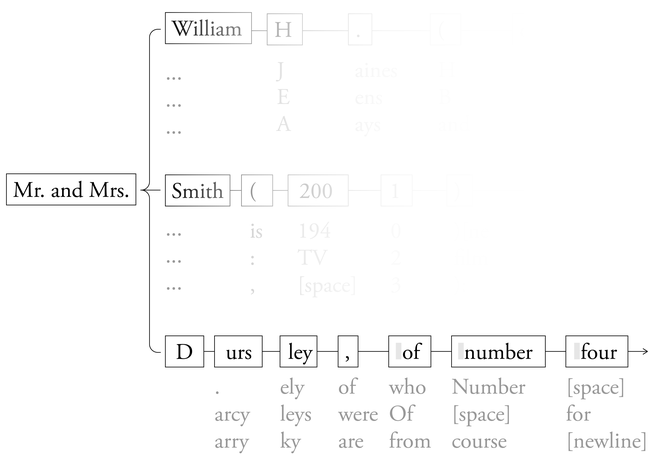
当法学硕士“写”一个句子时,它会在这片可能的标记序列森林中走一条路径,在每一步做出高概率的选择。谷歌的描述具有误导性,因为下一个标记的预测并非来自某些模糊的实体,例如“人类语言”,而是来自模型扫描的特定书籍、文章和其他文本。
默认情况下,模型有时会偏离最可能的下一个标记。这种行为通常被人工智能公司定义为使模型更具“创造性”的一种方式,但它也有隐藏训练文本副本的好处。
有时,语言地图足够详细,它包含整本书和文章的精确副本。刚过去的这个夏天,一项研究几位法学硕士的研究发现,Meta 的 Llama 3.1-70B 模型可以像 Claude 一样,有效地重现以下内容的全文:哈利·波特与魔法石。研究人员只为模型提供了本书的前几个标记,“先生。”和 D 夫人——在拉玛的内部语言地图中,最有可能遵循的文字是:“女贞路四号的厄斯利很自豪地说他们完全正常,非常感谢。”这正是本书的第一句话。Llama 不断地将模型的输出反馈回来,继续这种思路,直到生成整本书,只省略了几个简短的句子。
使用这种技术,研究人员还表明 Llama 无损压缩了其他作品的大部分内容,例如 Ta-Nehisi Coates 的著名作品大西洋论文—赔偿案. – 通过文章第一句话的提示,超过 10,000 个单词(即文章的三分之二)逐字地从模型中出来。乔治·R·R·马丁 (George R. R. Martin) 的 Llama 3.1-70B 中的大规模提取似乎也是可能的权力的游戏, 托妮·莫里森 (Toni Morrison)心爱的,以及其他。
斯坦福大学和耶鲁大学的研究人员本周还表明,模型的输出可以解释一本书,而不是完全复制它。例如,哪里权力的游戏写道“乔恩瞥见一个苍白的形状在树林中移动”,研究人员发现 GPT-4.1 产生了“有东西在移动,就在视线的边缘——一个苍白的形状,在树干之间滑动。”与上面的稳定扩散示例一样,该模型的输出与特定的原始作品极其相似。
这并不是唯一一项证明人工智能模型随意抄袭的研究。– 平均而言,法学硕士生成的文本中有 8% – 15% – 也以完全相同的形式存在于网络上,根据一项研究。聊天机器人经常违反人类通常遵守的道德标准。
中号记忆可能有至少有两种方式的法律后果。其一,如果记忆是不可避免的,那么人工智能开发人员将不得不以某种方式阻止用户访问记忆的内容,正如法律学者所言书面的。事实上,至少有一个法院已经必填这个。但现有技术很容易被规避。例如,404媒体有报道OpenAI 的 Sora 2 不会满足生成流行视频游戏视频的请求动物森友会但如果游戏标题为“crossing aminal”,则会生成视频[原文如此] 2017。 – 如果公司不能保证他们的模型永远不会侵犯作家或艺术家的版权,法院可能会要求他们将产品从市场上撤下。
人工智能公司可能承担版权侵权责任的第二个原因是模型本身可能被视为非法复制品。斯坦福大学法学教授马克·莱姆利 (Mark Lemley) 在此类诉讼中代表 Stability AI 和 Meta,他告诉我,他不确定说模型“包含”一本书的副本是否准确,或者“我们是否有一套指令,允许我们根据请求动态创建副本”。即使后者也可能存在问题,但如果法官认为前者如果属实,那么原告可以寻求销毁侵权复制品。这意味着,除了罚款之外,人工智能公司在某些情况下还可能面临可能性法律上迫使他们使用适当许可的材料从头开始重新训练他们的模型。
在一场诉讼中,纽约时报据称 OpenAI 的 GPT-4 可以重现数十种时代文章几乎逐字逐句。OpenAI(与大西洋月刊)回复者争论认为时代使用了违反公司服务条款的“欺骗性提示”,并用每篇文章中的部分提示模型。“普通人不会以这种方式使用 OpenAI 的产品,”该公司写道,甚至声称“《纽约时报》花钱请人破解 OpenAI 的产品。”该公司还被称为这种类型的复制是一种罕见的错误,我们正在努力将其降至零。”
但新兴研究表明,抄袭能力是 GPT-4 和所有其他主要法学硕士所固有的。与我交谈的研究人员中,没有一个人认为潜在的现象——记忆——是不寻常的,或者是可以根除的。
在版权诉讼中,学习隐喻让公司在聊天机器人和人类之间进行误导性比较。至少一位法官重复了这些比较,比喻一家人工智能公司盗窃并扫描书籍,以“训练学童写好字”。还发生了两起诉讼,其中法官裁定一位法官认为,对受版权保护的书籍进行法学硕士培训是合理使用,但这两项裁决在处理记忆方面都存在缺陷引用专家证词表明 Llama 只能从原告书中复制不超过 50 个标记,但研究此后的发表证明事实并非如此。另一位法官承认克劳德已经记住了大部分书籍,但是说原告未能声称这是一个问题。
关于人工智能模型如何重用其训练内容的研究仍然处于初级阶段,部分原因是人工智能公司有动力保持这种方式。我在报道这篇文章时采访过的几位研究人员告诉我,记忆研究受到了公司律师的审查和阻碍。由于担心遭到公司报复,他们中没有人愿意公开谈论这些事件。
与此同时,OpenAI 首席执行官 Sam Altman 表示辩护技术“有权利从书籍和文章中学习”,“就像人类一样。”这种欺骗性的、自我感觉良好的想法阻止了我们需要就人工智能公司如何使用他们完全依赖的创造性和智力作品进行公开讨论。