

尽管商业环境中信息和数据泛滥,员工和利益相关者常常发现自己在寻找信息时遇到困难,并且难以快速高效地获得问题的答案。这可能导致生产力下降、沮丧情绪以及决策延迟。
一个生成式AISlack聊天助手可以通过提供一个用户可以交互并获取所需信息的智能界面来帮助解决这些挑战。通过使用生成式AI的自然语言处理和生成能力,聊天助手可以理解用户的查询,从各种数据源检索相关信息,并提供定制化的、上下文相关的回复。
通过利用生成式人工智能的力量和亚马逊网络服务(AWS)服务亚马逊Bedrock, 亚马逊 Kendra,和 亚马逊莱克斯该解决方案提供了一个示例架构,用于构建一个智能的Slack聊天助手,以简化信息访问、增强用户体验并提高组织内的生产力和效率。
为什么使用Amazon Kendra来构建RAG应用程序?
亚马逊 Kendra 是一项完全托管的服务,提供了开箱即用的语义搜索功能,用于对文档和段落进行先进的排名。您可以使用 Amazon Kendra 来快速为企业数据构建高精度的生成式AI应用程序并获取最相关的文档和内容,以最大化检索增强生成(RAG)载荷的质量,从而比使用传统或基于关键词的搜索解决方案产生更好的大型语言模型(LLM)响应。Amazon Kendra 提供了易于使用的深度学习搜索模型,这些模型预先在14个领域进行了训练,并且不需要机器学习(ML)专业知识。Amazon Kendra 可以从各种来源索引内容,包括数据库、内容管理系统、文件共享和网页。
此外,Amazon Kendra中的FAQ功能补充了服务的更广泛的检索能力,允许RAG系统无缝地在提供预写入的FAQ响应和通过查询更大的知识库动态生成响应之间切换。这使其非常适合为RAG系统的检索组件提供动力,使模型在生成响应时能够访问广泛的知识库。通过集成Amazon Kendra 的常见问题解答功能将模型集成到检索增强生成(RAG)系统中,可以使模型使用一组经过精心策划的高质量、权威的答案来回答常见问题。这可以提高整体响应质量和服务体验,同时减少语言模型从头开始生成这些基本回复的压力。
该解决方案在保留模型选择、提示工程和添加FAQ等方面的自定义与无需处理词嵌入、文档分块及其他RAG实现通常所需的低级复杂性之间取得了平衡。
解决方案概览
聊天助手旨在通过回答用户的问题并提供各种主题的信息来协助用户。聊天助手的目的是成为一个面向内部的Slack工具,可以帮助员工和利益相关者找到他们需要的信息。
该架构使用Amazon Lex进行意图识别,AWS Lambda用于处理查询,使用Amazon Kendra通过FAQ和网页内容进行搜索,并利用大型语言模型(LLM)由Amazon Bedrock生成情境化响应。通过结合这些服务,聊天助手可以理解自然语言查询,从多个数据源检索相关信息,并提供符合用户需求的类人化回复。该解决方案展示了生成式AI在创建智能虚拟助手方面的力量,这种虚拟助手可以根据模型选择、FAQ和修改系统提示及推理参数来简化工作流程并增强用户体验。
架构图
以下图表说明了一种RAG方法,其中用户通过Slack应用程序发送查询,并接收基于Amazon Kendra中索引的数据生成的响应。在本文中,我们使用Amazon Kendra网络爬虫作为数据源,并包含存储在其中的FAQ。亚马逊简单存储服务(Amazon S3)。参见数据源连接器亚马逊Kendra支持的数据源连接器列表。

该架构的分步工作流程如下:
- 用户发送一个查询,例如
什么是AWS良好架构框架?通过Slack应用程序。 - 查询发送到Amazon Lex,后者识别意图。
- 当前在Amazon Lex中配置了两个意图
欢迎和回退意图fallbackintent(在中文语境中通常会同时给出技术术语的英文和译文以便理解)). - 欢迎意图配置为在用户输入“你好”或“ hello”等问候语时进行回应。助理会回复说:“你好!我可以根据提供的文档帮助您解答问题。问问我吧。”
- 备用意图通过一个Lambda函数来实现。
- Lambda函数通过查询Amazon Kendra常见问题解答来执行搜索。
Kendra FAQ搜索通过将用户查询和Amazon Kendra索引ID作为输入来实现。如果匹配度高且信心分数较高,则从FAQ中返回答案给用户。def search_Kendra_FAQ(question, kendra_index_id): """ 此函数接收来自用户的提问,并检查该问题是否存在于Kendra的FAQ中。 :param question: 用户通过前端输入文本框提出的问题。 :param kendra_index_id: 包含文档和FAQ的Kendra索引 :return: 如果在FAQ中找到,返回答案以及任何相关链接。如果没有找到,则返回False并调用kendra_retrieve_document函数。 """ kendra_client = boto3.client('kendra') response = kendra_client.query(IndexId=kendra_index_id, QueryText=question, QueryResultTypeFilter='QUESTION_ANSWER') for item in response['ResultItems']: score_confidence = item['ScoreAttributes']['ScoreConfidence'] # 仅从具有非常高置信度分数的FAQ中提取答案 if score_confidence == 'VERY_HIGH' and len(item['AdditionalAttributes']) > 1: text = item['AdditionalAttributes'][1]['Value']['TextWithHighlightsValue']['Text'] url = "None" if item['DocumentURI'] != '': url = item['DocumentURI'] return (text, url) return (False, False) - 如果匹配的置信度分数不够高,通过Amazon Kendra检索具有高置信度分数的相关文档。
Kendra_检索文档方法并发送到Amazon Bedrock以生成响应作为上下文。def kendra_retrieve_document(question, kendra_index_id): """ 该函数接收来自用户的提问,并根据默认的 PageSize(10)检索相关段落。 :param question: 用户通过前端输入文本框提出的问题。 :param kendra_index_id: 包含文档和FAQs的 Kendra 索引 :return: 返回要发送给大语言模型的上下文以及作为相关数据源的文档 URI。 """ kendra_client = boto3.client('kendra') documents = kendra_client.retrieve(IndexId=kendra_index_id, QueryText=question) text = "" uris = set() if len(documents['ResultItems']) > 0: for i in range(len(documents['ResultItems'])): score_confidence = documents['ResultItems'][i]['ScoreAttributes']['ScoreConfidence'] if score_confidence == 'VERY_HIGH' or score_confidence == 'HIGH': text += documents['ResultItems'][i]['Content'] + "\n" uris.add(documents['ResultItems'][i]['DocumentURI']) return (text, uris) - 该响应由Amazon Bedrock生成
调用LLM方法。以下是一段代码片段:调用LLM在实现功能的方法中。阅读更多关于推理参数以及系统提示修改传递到Amazon Bedrock调用模型请求中的参数。def 调用LLM(question, context, modelId): """ 此函数接收来自用户的问题,以及Kendra的响应作为上下文,在前端为用户提供答案。 :param question: 用户通过前端输入文本框提出的问题。 :param documents: 来自Kendra文档检索查询的响应,用作生成更好回答的上下文。 :return: 返回应用程序最终用户的原始问题的回答。 """ # 设置Bedrock客户端 bedrock = boto3.client('bedrock-runtime') # 配置模型的具体信息,例如特定模型 modelId = modelId # 传递到Bedrock调用模型请求的数据主体 body = json.dumps({"max_tokens": 350, "system": "你是一个诚实的AI助手。你的目标是基于提供的文档提供有见地和实质性的回答。如果你不知道某个问题的答案,你应该诚实地说明这一点。", "messages": [{"role": "user", "content": "用以下上下文回答用户的问题:" + question + context}], "anthropic_version": "bedrock-2023-05-31", "temperature": 0, "top_k": 250, "top_p": 0.999}) # 使用您的规范调用Bedrock模型 response = bedrock.invoke_model(body=body, modelId=modelId) # 生成的响应正文 response_body = json.loads(response.get('body').read()) # 获取特定完成字段,该字段包含您的回答 answer = response_body.get('content') # 返回最终结果作为回答,这最终返回给最终用户 return answer - 最后,由Amazon Bedrock生成的响应及相关引用的URL返回给最终用户。
在选择网站进行索引时,遵守亚马逊网络服务适用政策以及其它AWS术语。请记住,您只能使用Amazon Kendra网络爬虫来索引自己的网页或您有权索引的网页。访问该网站:亚马逊 Kendra 网页抓取器数据源指南,了解更多关于将网络爬虫用作数据源的信息。使用Amazon Kendra 网络爬虫来积极抓取您不拥有的网站或网页是不视为可接受使用。
支持的功能
聊天助手支持以下功能:
- 支持以下Anthropic模型在Amazon Bedrock上:
claude-v2claude-3-haiku-20240307-v1:0claude-instant-v1克洛德-3-十四行诗-20240229-v1:0
- 支持FAQ和Amazon Kendra网络爬虫数据源
- 仅在信心分数达到要求时返回FAQ答案
非常高 - 仅检索来自Amazon Kendra且具有某个条件的文档(原文中"have a"后的内容缺失,故此处保留以示完整)
高或非常高置信分数 - 如果得分高的文档没有找到,聊天助手会返回“未找到相关文档”
先决条件
要执行该解决方案,您需要具备以下先决条件:
- AWS基础知识
- 一个AWS账户具有访问Amazon S3和Amazon Kendra的权限
- 一个S3桶用于存储您的文档。更多信息请参见步骤1:创建您的第一个S3桶以及亚马逊S3用户指南.
- 一个用于集成聊天机器人的Slack工作区
- 安装Slack应用到您的Slack工作区的权限
- Amazon Kendra 网页爬虫数据源的种子 URL
- 您需要授权才能抓取和索引任何提供的网站
- AWS云formation部署解决方案资源
构建一个生成式AI Slack聊天助手
要构建一个Slack应用,请使用以下步骤:
- 请求访问Amazon Bedrock模型对于所有Anthropic模型
- 创建一个S3桶在
美国东部1区(A. 佛吉尼亚北部) AWS 区域。 - 上传theAI机器人-词典json.zip以及样本FAQ.csv将文件上传到S3桶中
- 启动CloudFormation堆栈在
美国东部1区(A. 弗吉尼亚) AWS 区域。
- 请输入一个堆栈名称您选择的
- 对于S3桶名称输入在步骤2中创建的S3桶的名称
- 对于S3KendraFAQKey,输入名称的
示例FAQs上传到步骤3中的S3桶中 - 对于S3LexBotKey在步骤3中上传到S3桶的Amazon Lex .zip文件的名称
- 对于种子URLs请输入最多10个URL供网络爬虫使用,以逗号分隔。在本文的示例中,我们提供公开可用的Amazon Bedrock服务页面作为种子URL。
- 保持其余选项为默认设置。选择下一个请选择下一个再次在该日期национальный текст уже на китайском языке или не содержит информации для перевода, поэтому предоставляю оригинальный текст (или сообщение о его отсутствии): again on the配置堆栈选项
- 通过选框确认并选择提交如以下截图所示

- 等待堆栈创建完成
- 验证所有资源是否已创建完毕
- 在Amazon Lex的AWS管理控制台中进行测试
- 在Amazon Lex控制台上,选择您的聊天助手
${您的堆栈名称}-AI机器人 - 选择意图
- 选择版本 1并选择测试如以下屏幕截图所示
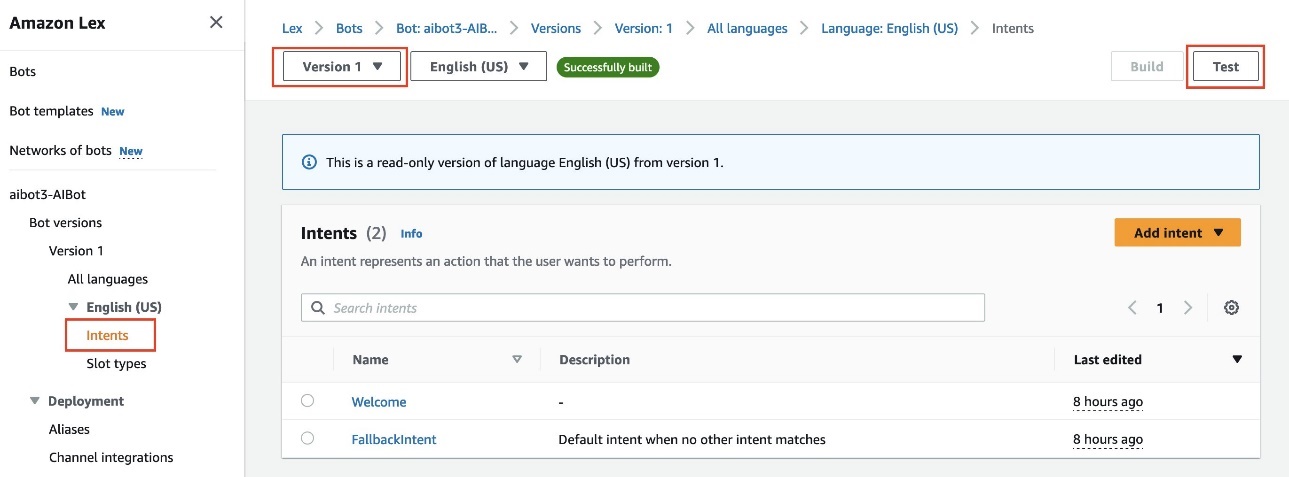
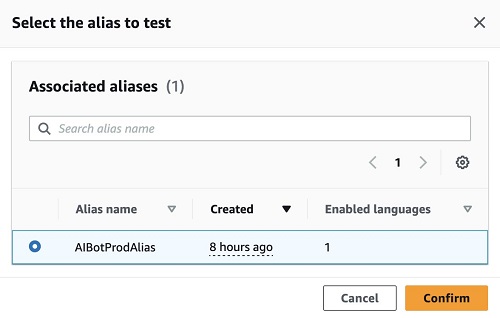
- 选择AI机器人产品别名并选择确认如下截图所示。如果您想对聊天助手进行更改,可以使用草稿版本,发布新版本,并将新版本分配给
AI机器人产品别名了解更多关于版本控制和别名.
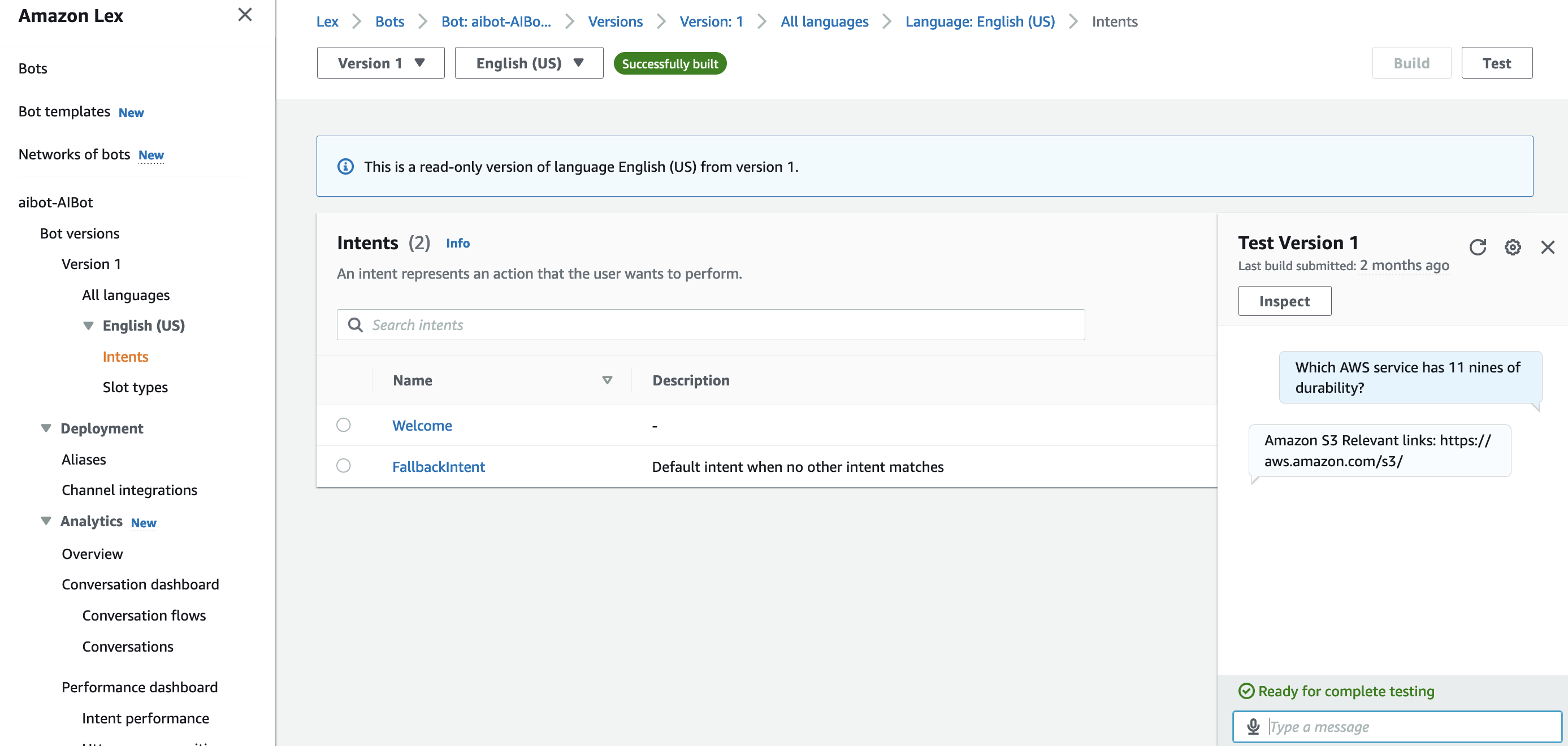
- 用诸如“哪个AWS服务具有11个九的持久性?”和“什么是AWS Well-Architected框架?”等问题来测试聊天助手,并验证其响应。以下表格显示了示例.csv文件中有三个FAQ。
问题 答案 源_URI 哪个AWS服务具有11九的持久性? 亚马逊S3 https://aws.amazon.com/s3/ AWS完善架构框架是什么? AWS Well-Architected框架使客户和合作伙伴能够采用一致的方法来审查其架构,并提供指导以逐步改进设计。 https://aws.amazon.com/cn/architecture/well-architected/ Amazon Kendra 在哪些区域可用? 亚马逊 Kendra 目前在以下 AWS 区域可用:弗吉尼亚北部、俄勒冈和爱尔兰 https://aws.amazon.com/about-aws/global-infrastructure/regional-product-services/ - 以下截图显示了问题
“哪个AWS服务具有十一九的持久性?”请注意,“十一九的持久性”这里的表达可能不够准确,原文可能是想表达“11个9的耐久度”,在中文里通常会更明确地说成“具备11个9持久性的服务”。具体根据上下文理解为“AWS中哪个服务具有极高的(11个9)数据持久性和耐久性保障。”以及它的回复。你可以观察到回复与FAQ文件中的相同,并包含一个链接。
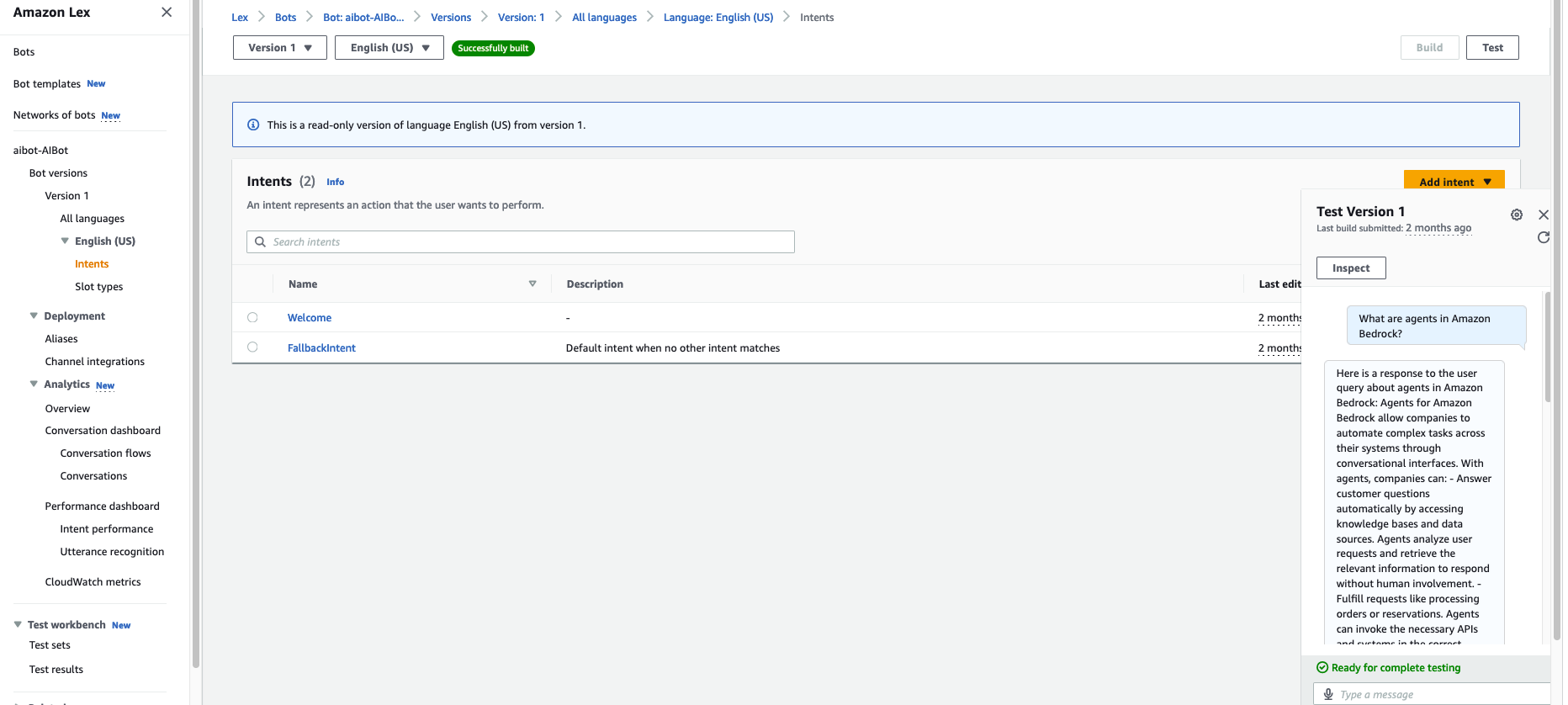
- 根据你抓取的页面,在聊天中提问。在这个例子中,抓取并索引了公开的Amazon Bedrock页面。以下截图显示了问题,
什么是Amazon Bedrock中的代理?以及包含相关链接的生成回复。
- 在Amazon Lex控制台上,选择您的聊天助手
- 有关将Amazon Lex聊天机器人与Slack集成的内容,请参见将Amazon Lex V2机器人与Slack集成请选择AI机器人产品别名低于别名在渠道集成
运行示例查询以测试解决方案
- 在Slack中,进入应用程序部分。在下拉菜单中选择管理并选择浏览应用.
- 搜索
${AI机器人}在应用目录并选择聊天助手。这会将聊天助手添加到Slack的应用部分。你现在可以开始在聊天中提问了。下图显示了问题提问的情形。“哪个AWS服务具有11九的持久性?”以及它的响应。你可以观察到该响应与FAQ文件中的相同,并包含一个链接。

- 以下截图显示了问题,
什么是AWS良好架构框架?及其响应。

- 根据你抓取的页面,在聊天中提问。在这个例子中,公开可用的Amazon Bedrock页面已被抓取并索引。以下截图显示了问题,
什么是Amazon Bedrock中的代理?以及包含相关链接的生成回复。
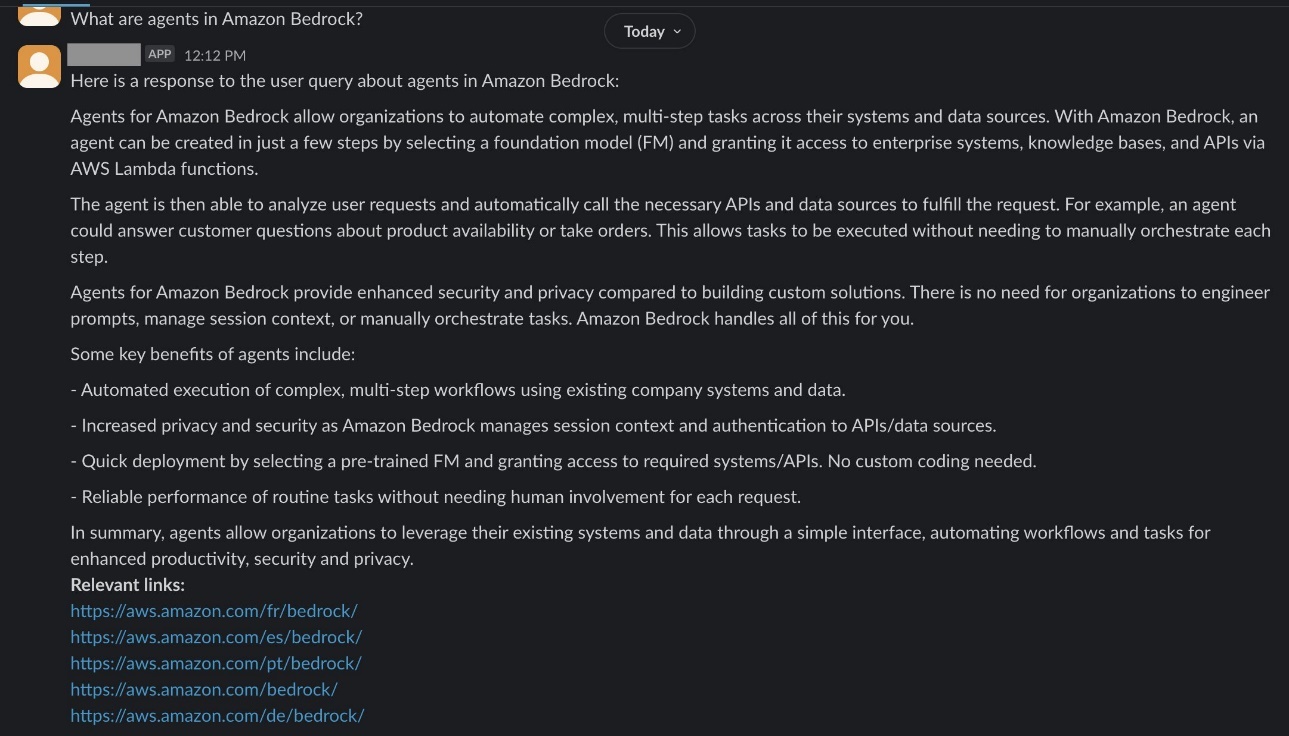
- 以下截图显示了问题,
什么是Amazon Polly?由于没有索引亚马逊波利(Amazon Polly)文档,聊天助手如预期地回应“未找到相关文档”。

这些示例展示了聊天助手如何从Amazon Kendra检索文档并根据检索到的文档提供答案。如果没有找到相关文档,聊天助手将回应“未找到相关文档。”
清理一下
清理由该解决方案创建的资源:
- 通过导航到CloudFormation控制台删除CloudFormation堆栈
- 选择你为此解决方案创建的堆栈,并进行选取删除
- 通过在提供的字段中输入堆栈名称来确认删除。这将移除CloudFormation模板创建的所有资源,包括Amazon Kendra索引、Amazon Lex聊天助手、Lambda函数及其他相关资源。
结论
本文描述了一个由Amazon Bedrock和Amazon Kendra驱动的生成式AI Slack应用的开发过程。该应用是一个面向内部的Slack聊天助手,旨在帮助回答与索引内容相关的问题。解决方案架构包括使用Amazon Lex进行意图识别、Lambda函数用于实现备用意图、Amazon Kendra用于FAQ搜索及抓取网页的索引,并且利用Amazon Bedrock生成回复。文章详细介绍了如何通过CloudFormation模板部署该方案、提供了运行示例查询的说明以及清理资源的步骤。总的来说,本文展示了如何使用各种AWS服务构建一个强大的生成式AI驱动的聊天助手应用。
此解决方案展示了生成式AI在构建智能聊天助手和搜索助手方面的强大能力。探索生成式AI的Slack聊天助手:邀请您的团队加入一个Slack工作区,并开始获取您索引的内容和常见问题的答案。尝试不同的用例,看看如何利用Amazon Bedrock和Amazon Kendra等服务的功能来增强您的业务运营。有关将Amazon Bedrock与Slack结合使用的更多信息,请参阅部署一个用于Amazon Bedrock的Slack网关.
关于作者
 克鲁希·杰亚西姆哈·拉奥是一位专注于人工智能和机器学习的合作伙伴解决方案架构师。她为AWS合作伙伴提供技术指导,帮助他们在AWS云中遵循最佳实践来构建安全、可靠且高度可用的解决方案。
克鲁希·杰亚西姆哈·拉奥是一位专注于人工智能和机器学习的合作伙伴解决方案架构师。她为AWS合作伙伴提供技术指导,帮助他们在AWS云中遵循最佳实践来构建安全、可靠且高度可用的解决方案。 穆罕默德·莫哈默德穆罕默德是一名专注于数据 analytics 的合作伙伴解决方案架构师。他专长于流式分析,帮助合作伙伴在 AWS 上构建实时数据管道和分析解决方案。凭借对 Amazon Kinesis、Amazon MSK 和 Amazon EMR 等服务的深厚了解,穆罕默德通过流式分析助力基于数据的决策制定。
穆罕默德·莫哈默德穆罕默德是一名专注于数据 analytics 的合作伙伴解决方案架构师。他专长于流式分析,帮助合作伙伴在 AWS 上构建实时数据管道和分析解决方案。凭借对 Amazon Kinesis、Amazon MSK 和 Amazon EMR 等服务的深厚了解,穆罕默德通过流式分析助力基于数据的决策制定。 - Lambda函数通过查询Amazon Kendra常见问题解答来执行搜索。
