

AI 代理的内存扩展
推理扩展使法学硕士能够在大多数实际情况下进行推理,只要他们有正确的背景。对于许多现实世界的智能体来说,瓶颈不再是推理能力,而是使智能体获得正确的信息:为模型提供当前任务所需的信息。
这为代理设计提出了一个新的轴。我们不应该仅仅关注更强的模型或更好的提示,而是可以问:当智能体积累更多信息时,它是否会变得更好?我们称之为内存扩展:代理性能随着过去对话量、用户反馈、交互轨迹(成功和失败)以及存储在内存中的业务上下文而提高的属性。这种效果在企业环境中尤其明显,因为部落知识丰富,单个代理可以为许多用户提供服务。
但这并不是显而易见的先验。更多的内存并不会自动使代理变得更好:低质量的跟踪可能会带来错误的教训,并且随着存储的增长,检索会变得更加困难。核心问题是智能体是否可以有效地使用更大的记忆,而不是简单地积累它们。
我们已经在 Databricks 朝这个方向迈出了早期的一步:急性心力衰竭和内存对齐,根据人类反馈调整代理行为,以及指导猎犬,它使搜索代理能够将复杂的自然语言指令和知识源模式转换为精确的结构化搜索查询。这些系统共同证明,代理可以通过持久记忆提供更多帮助。这篇文章展示了展示内存扩展行为的实验结果,讨论了在生产中支持它所需的基础设施,并提供了基于内存的代理的前瞻性愿景。
什么是内存缩放?
内存扩展是代理的性能随着其外部内存的增长而提高的属性。这里的“内存”是指代理在推理时可以与之交互的信息的持久存储,与模型的权重或当前上下文窗口不同。
这使得内存扩展成为参数扩展和推理时间扩展的一个独特且互补的轴,解决了领域知识中的差距,并奠定了模型大小和推理能力都无法自行弥补的基础。内存扩展带来的改进不仅限于答案质量。当代理记住环境的相关模式、域规则或过去成功的操作时,它可以跳过冗余探索并更快地解决查询。在我们的实验中,我们观察到准确性和效率的扩展。
与持续学习的关系
持续学习通常侧重于随着时间的推移更新模型参数,这在以下情况下效果很好有界的但对于许多并发用户、代理和快速变化的项目来说,计算成本会变得昂贵且脆弱。内存扩展提出了一个不同的问题:拥有数千个用户的代理是否比拥有单个用户的代理表现更好?通过扩展代理的共享外部状态,同时保持 LLM 权重冻结,答案可能是肯定的——可以检索从一个用户学到的工作流程模式并立即应用于另一个用户,而无需任何重新训练。这是持续学习的一个特性,因为它专注于单个用户的模型参数更新,所以从来没有被设计来提供。
与长上下文的关系
大型上下文窗口可能看起来像是内存的替代品,但它们解决了不同的问题。将数百万个原始标记打包到提示中会增加延迟,提高计算成本,并降低推理质量,因为不相关的标记会争夺注意力。相反,记忆扩展依赖于选择性检索——不仅决定要包含多少上下文,还要决定包含什么,仅显示与当前任务相关的高信号信息。
记忆的类型
并非所有记忆都有相同的用途。在实践中,有两个区别很重要:
情景与语义。情景记忆是过去交互的原始记录——对话日志、工具调用轨迹、用户反馈。语义记忆是从这些交互中提取的概括技能和事实(例如,“这个领域的用户在说‘季度’时总是指财政季度”)。每种类型都需要不同的存储、处理和检索策略:用于直接检索的情景记忆和由法学硕士提取的用于更广泛模式匹配的语义记忆。
个人与组织。有些记忆是特定于单个用户的偏好和工作流程的;其他代表共享的组织知识——命名约定、常见查询、业务规则。记忆系统必须适当地调整检索和更新的范围:广泛地呈现组织知识,同时保持个人上下文的私密性,尊重权限和 ACL。
实验:Genie Space 上的 MemAlign内存对齐
是我们对人工智能代理的简单记忆框架的探索。它将过去的交互存储为情景记忆,使用法学硕士将它们提炼成通用规则和模式(语义记忆),并在推理时检索最相关的条目来指导代理。有关框架的详细信息,请参阅我们的之前的博客文章。
我们测试了 MemAlignDatabricks 精灵空间,一个自然语言界面,业务用户可以用简单的英语询问数据问题并接收基于 SQL 的答案。下面提供了任务查询和答案的示例
我们的目标是使用两个数据源来衡量代理性能如何随着我们为其提供更多内存而扩展:精选示例(已标记)和原始用户对话日志(未标记)。
使用标记数据进行缩放
我们针对分布在 10 个 Genie 空间中的未见问题评估了 MemAlign,逐步将带注释的训练示例碎片添加到代理的内存中。我们的基线是使用专家策划的 Genie 指令(手动编写的表模式、域规则和少量示例)的代理。
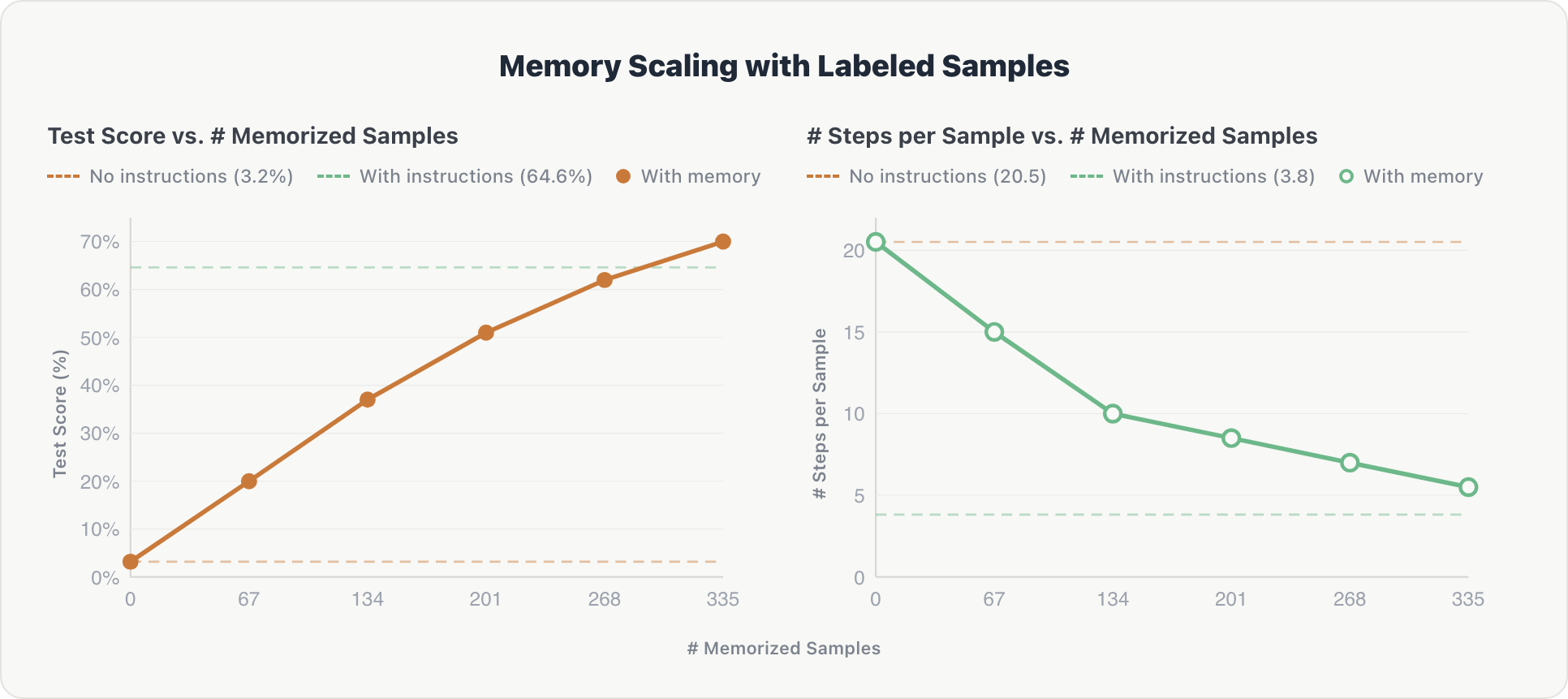
结果显示沿两个维度的缩放比例一致:
准确性。每增加一个内存碎片,测试分数就会稳步上升,从接近零上升到 70%,最终超出专家制定的基线约 5%。经过检查,人工标记的数据被证明比手动编写的表模式和域规则更全面,因此更有用。
效率。随着内存的增长,每个示例的平均推理步骤数从约 20 减少到约 5。代理学会直接检索相关上下文,而不是从头开始探索数据库,接近硬编码指令的效率(约 3.8 个步骤)。
效果是累积性的:因为记忆的样本跨越 10 个不同的 Genie 空间,每个分片都会贡献基于先验知识的跨域信息。
使用未标记的用户日志进行扩展
内存可以适应嘈杂的现实世界数据吗?为了找到答案,我们在实时 Genie 空间中运行 MemAlign,并向其提供历史用户对话日志,但没有黄金答案。一位法学硕士法官筛选了这些日志的有用性,并且只记住了高质量的日志。
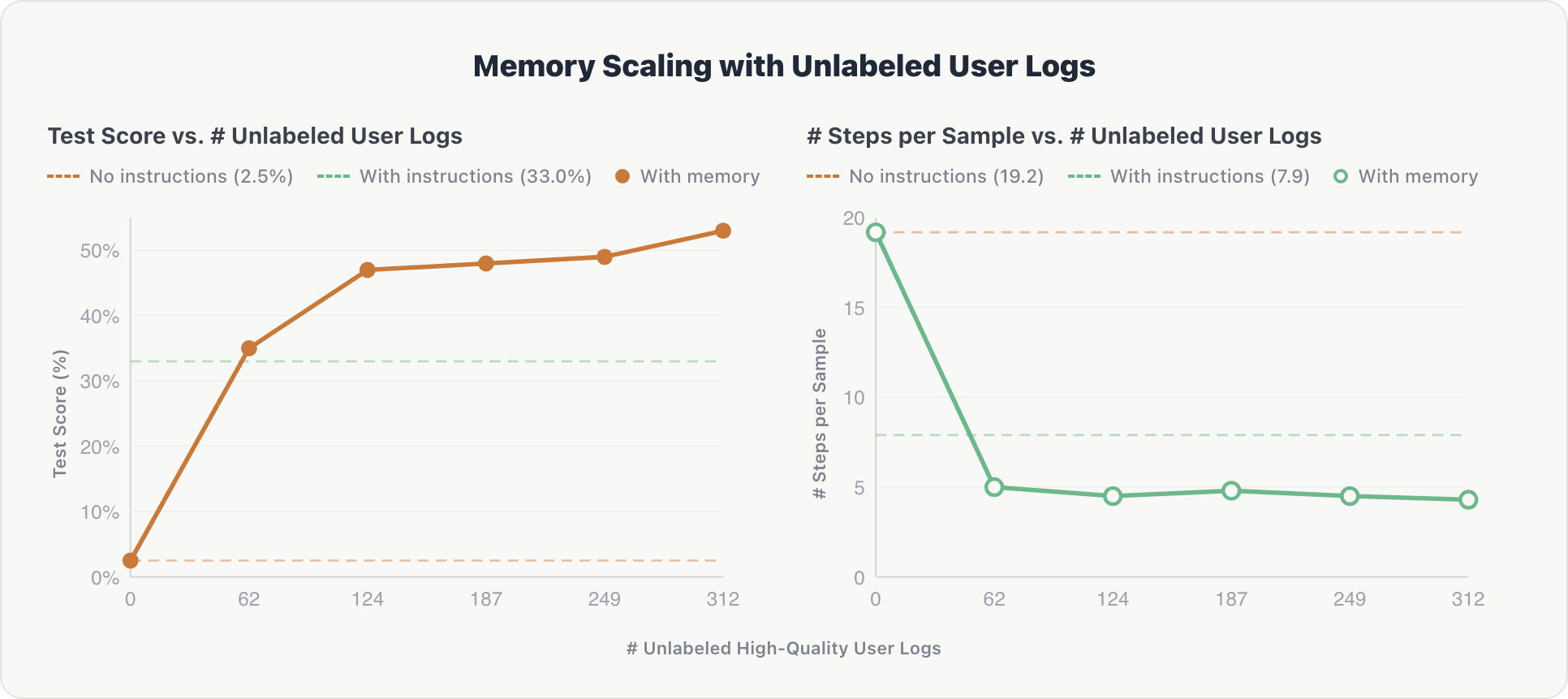
缩放曲线遵循类似的模式,并且在开始时更陡:
准确性。该代理最初表现出巨大的收益。在第一个日志分片之后,它提取有关相关表和隐式用户首选项的关键信息。仅 62 条日志记录后,性能就从 2.5% 上升到 50% 以上,超过了专家制定的基线 (33.0%)。
效率。在第一个分片之后,推理步骤从 ~19 下降到 ~4.3 并保持稳定。代理尽早内化了空间的模式,并避免了后续查询的冗余探索。
要点:未经策划的用户交互,仅由自动化、无参考判断过滤,可以替代昂贵且耗时的手工设计的领域指令。这也表明代理可以在正常使用的基础上不断改进,并且可以超越人类注释的限制。
实验:组织知识库
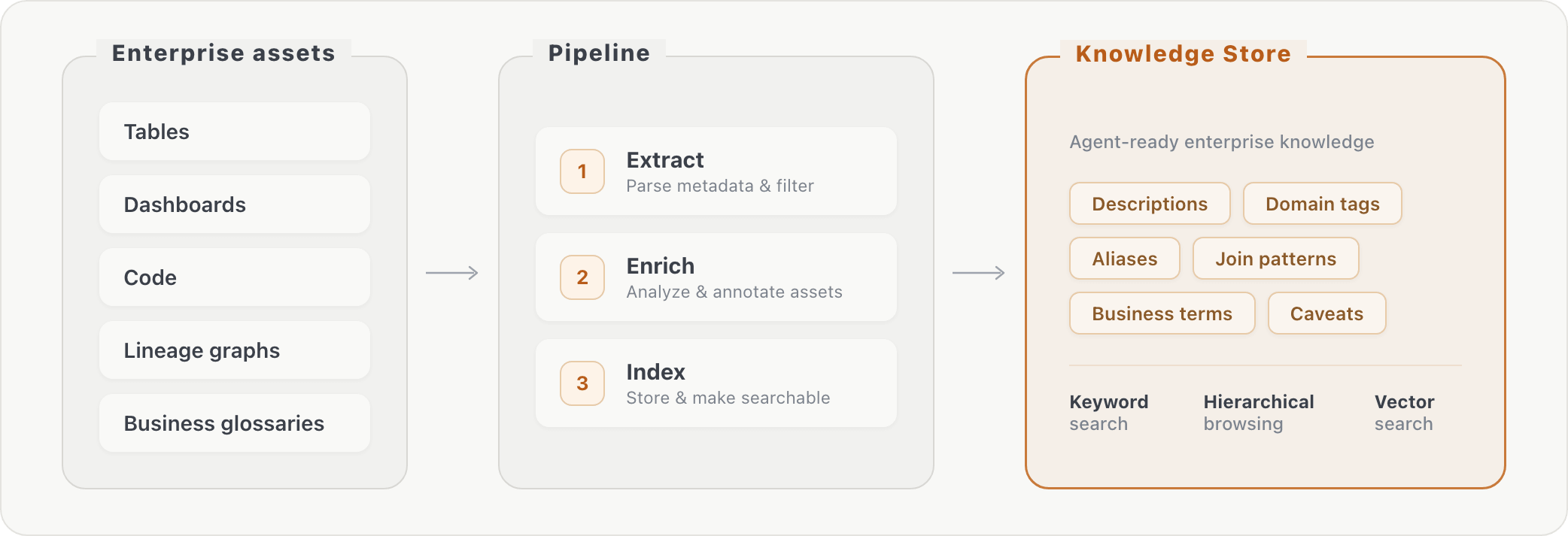
上面的实验展示了内存扩展如何随着用户交互而发生。但企业也拥有早于任何用户交互的现有知识:表模式、仪表板查询、业务术语表和内部文档。我们测试了将这些组织知识预先计算到结构化内存存储中是否可以提高代理性能。
我们根据内部数据研究基准和PMBench,它测试对混合内部文档(例如产品经理会议记录和计划材料)的详尽事实搜索。
我们的管道分三个阶段将原始数据库元数据处理为可检索的知识:(1)提取有关资产的信息,(2)通过额外的转换丰富资产,以及(3)对丰富内容建立索引。在查询时,代理可以通过关键字搜索或分层浏览来查找企业上下文。这弥合了业务用户如何表达问题(“人工智能消耗”)和数据实际存储方式(特定表中的特定列名称)之间的差距。
添加知识存储将两个评估基准的准确性提高了大约 10%。收益集中在需要词汇桥接、表连接和列级知识的问题上,即代理无法仅通过模式探索发现的信息。
内存扩展基础设施
企业部署中的内存扩展需要一个超越简单向量存储的强大基础设施。接下来,我们将讨论该基础设施需要解决的三个关键挑战:可扩展存储、内存管理和治理。
可扩展存储
最简单的内存存储是文件系统:分层文件夹中的 Markdown 文件,使用标准 shell 工具浏览和搜索。基于文件的内存在小规模和个人用户中效果很好,但它缺乏索引、结构化查询和有效的相似性搜索。随着许多用户的内存增长到数千个条目,检索性能会下降,治理也变得难以执行。
专用数据存储是自然的下一步。独立矢量数据库可以很好地处理语义搜索,但缺乏连接和过滤等关系功能。现代基于 PostgreSQL 的系统提供了更统一的替代方案:它们本身支持单个引擎中的结构化查询、全文搜索和向量相似性搜索。
无服务器变体这种将存储与计算分离并提供低成本、持久存储的架构非常适合。我们一直在使用湖基,建立在霓虹灯的无服务器 PostgreSQL 引擎,这要归功于其扩展到 0 的成本以及对向量和精确搜索的支持。内置数据库分支还简化了开发周期——工程师可以分叉代理的内存状态进行测试,而不会影响生产。
内存管理
仅可扩展存储是不够的。内存系统还必须管理其内容:
- 自举。众所周知,新代理会遇到冷启动问题。通过文档解析和提取吸收现有的企业资产(维基、文档、内部指南)提供了一个初始记忆基础,可以缓解其中一些问题,正如我们的组织知识存储实验所证明的那样。
- 蒸馏。原始情景记忆对于直接检索很有用,但大规模存储和搜索会变得昂贵。定期将它们提炼成语义记忆(压缩的规则和模式)可以使记忆存储易于处理,并为代理提供可概括的见解,这可能仅从情景记忆中并不明显。
- 整合。随着内存的增长,保持系统一致、紧凑和最新非常重要。这需要管道删除重复项、修剪过时的信息并解决新旧条目之间的冲突。
安全性
内存引入了无状态代理所不存在的治理要求。随着代理积累深入的上下文知识,包括用户偏好、专有工作流程和内部数据模式,适用于企业数据的相同治理原则必须扩展到代理内存。
访问控制必须具有身份意识:个人记忆应保持私密,而组织知识可以在访问控制范围内共享。这自然地映射到平台喜欢的那种细粒度的权限统一目录已经对数据资产实施了强制措施,例如行级安全性、列屏蔽和基于属性的访问控制。
将这些控制扩展到内存条目意味着检索一个用户的上下文的代理不会无意中暴露另一用户的私人交互。
除了访问控制之外,数据沿袭和可审计性也很重要。当智能体的行为由其记忆决定时,团队需要追踪哪些记忆影响了给定的响应,以及这些记忆何时被创建或更新。合规性和监管要求,特别是在受监管的行业中,要求内存存储支持与基础数据相同的可观察性保证:完整的沿袭跟踪、保留策略以及根据请求清除特定条目的能力。
确保正确的内存到达正确的用户,并且只有该用户,是大规模设计的核心问题。
什么阻碍了
每个缩放轴最终都会遇到自己的瓶颈。参数缩放受到高质量训练数据供应的限制。推理时间缩放可能会演变成过度思考,较长的推理链会在不增加信号的情况下增加成本,最终随着序列长度的增加而降低性能。内存扩展也有类似的限制:质量、范围和访问问题。
内存质量很难维持。有些记忆从一开始就是错误的;随着时间的推移,其他人会变得错误。无状态代理会犯孤立的错误,但配备记忆的代理可以通过存储错误并在以后检索它作为证据,将错误变成重复错误。我们已经看到代理引用了早期运行中本身错误的笔记本,然后更加自信地重复使用这些结果。陈旧性更加微妙:学习了上季度模式的代理可能会继续查询此后已重命名或删除的表。摄入时过滤会有所帮助,但生产系统需要的不仅仅是过滤。他们需要出处、置信度估计、新鲜度信号和定期重新验证。
治理必须延伸到蒸馏。在整个组织中扩展记忆需要将重复的交互提炼成可重用的语义记忆。但抽象并不能消除敏感性。像“对于 Y 公司来说,加入 CRM、市场情报和合作伙伴关系表”之类的记忆可能看起来无害,但仍会泄露机密的收购兴趣。挑战在于如何使记忆具有广泛的用途,同时又不将私有模式转变为共享知识。访问控制和敏感度标签必须经得起蒸馏,而不仅仅是摄入。
有用的记忆可能仍然无法访问。即使记忆是准确且最新的,智能体仍然必须发现它的存在。检索本质上是元认知的:智能体必须决定向其内存存储询问什么,然后才能知道其中有什么。当它无法预见到相关记忆可能有帮助时,它永远不会发出正确的查询,而是会退回到缓慢、冗余的探索。在实践中,存储的知识和可访问的知识之间的差距可能是内存扩展的主要限制因素。
这些并不是反对内存扩展的论据。这些是仍然需要解决的研究问题,以使内存扩展变得稳健。核心问题不仅仅是存储更多历史记录;它教导代理如何找到正确的内存,如何正确使用它,以及如何保持它的最新状态和适当的范围。
展望未来:作为记忆的代理人
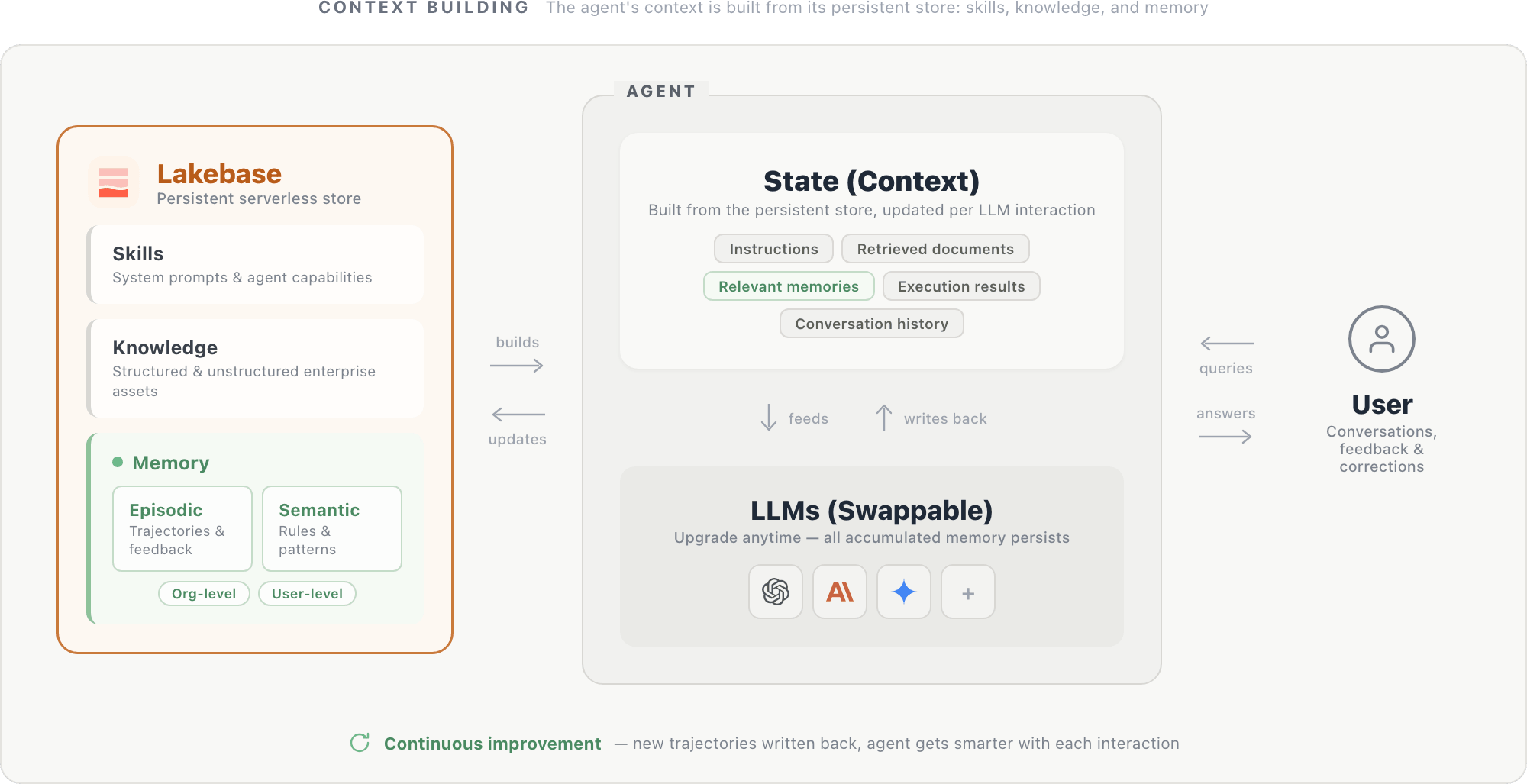
上面的实验和基础设施指向一种自然的设计模式:一个代理,其身份存在于其内存中,而不是其模型权重中。
在此设计中,代理的上下文是从位于无服务器数据库中的持久存储构建的,例如湖基。该商店包含三个组成部分:系统提示和代理能力(技能)、结构化和非结构化企业资产(知识)以及组织和用户级别的情景和语义记忆。这些组件共同构成了代理的状态:指令、检索到的文档、相关内存、执行结果(来自 SQL 查询、API 调用和其他工具)以及对话历史记录。该状态在每个步骤中都会馈送到 LLM,并在每次交互后更新。
LLM 本身是一个可交换的推理引擎:升级到更新的模型非常简单,因为新模型从相同的持久存储中读取并立即从所有累积的上下文中受益。
随着基础模型在功能上的趋同,企业代理的差异化因素将越来越多地取决于它们所积累的内存,而不是它们调用的模型。假设,具有丰富内存存储的较小模型可以胜过具有较少内存的较大模型 - 如果是这样,投资内存基础设施可能会比扩展模型参数产生更大的回报。特定于您的组织的领域知识、用户偏好和操作模式不在任何基础模型中。它们只能通过使用来构建,并且与模型功能不同,它们对于每个部署都是唯一的。
结论
我们提出内存扩展,代理通过用户交互和业务上下文将更多经验积累到内存中,从而提高性能。我们的初步实验表明,准确性和效率都与外部存储器中存储的信息量成正比。
在生产中实现这一点需要统一结构化和非结构化搜索的存储系统、保持内存一致性的管理管道以及适当限制访问范围的治理控制。这些都是现有技术可以解决的问题。回报是药剂随着持续使用而真正改善。
剩下的工作是大量的:随着内存的增长,内存必须保持准确、最新且可访问。但这正是内存扩展有趣的原因。它为构建代理打开了一个具体的系统和研究议程,通过针对每个组织和问题的特定方式持续使用,可以变得更好。
作者:詹文豪、吕云妮、刘嘉露、Michael Bendersky、Matei Zaharia、Xing Chen
我们要感谢 Kenneth Choi、Sam Havens、Andy Zhang、Ziyi Yang、Ashutosh Baheti、Sean Kulinski、Alexander Trott、Will Tipton、Gavin Peng、Rishabh Singh 和 Patrick Wendell 在整个项目中提供的宝贵反馈。