
一次性戳破人工智能泡沫神话
作者:Pau Blasco i Roca
misinformation和劣质研究:一个案例研究
![]()
![]()
不能忽视这样一个事实,即像ChatGPT这样的AI模型已经接管了互联网,渗透到了它的每一个角落。
大多数人工智能的应用都非常有用和有益对于各种任务(包括医疗、工程、计算机视觉、教育等)而言,我们没有理由不投资时间和金钱来发展它们。
这并不适用于生成式人工智能(GenAI),我将在本文中专门讨论这一领域。这包括大语言模型(LLMs)和检索增强生成(RAGs)等。ChatGPT、Claude、Gemini、Llama及其他模型我们必须非常具体地界定什么是人工智能、我们使用哪些模型以及它们的环境影响。
所以人工智能是否正在接管世界?它的智商是120吗?它能比人类更快、更好地思考吗?
AI热潮是指全社会围绕人工智能(尤其是类似变压器(GPT)模型)的普遍兴奋。它已经渗透到每一个领域——医疗、IT、经济、艺术等,并且贯穿整个生产链的每一层级。事实上,这是一个极其显著的现象,43%的高管和首席执行官已经使用生成式人工智能来指导战略决策 [2以下相关链接的文章将科技裁员与FAANG及其他大型公司中的人工智能使用联系起来。3, 4, 5].
AI热潮的影响也可以在股市中看到。英伟达公司的案例就是一个明显的例子:由于英伟达生产关键的硬件组件(GPU)来训练AI模型,其股价大幅上涨(这种增长可能并不反映公司实际的增长情况,而是更多地反映了市场对其重要性的感知)。
人类一直抗拒采纳新技术,尤其是那些他们不完全理解的技术。这是一次令人害怕的转变。每一次突破都感觉像是在与未知打赌——因此我们惧怕它。大多数人在确信新事物的实用性和安全性足以抵消风险之前不会转向使用它。然而,在某些事情扰乱我们的本能时就不同了,这些事情和恐惧一样基于情感:炒作。
生成式AI存在许多问题,其中大多数几乎是无法解决的。一些例子包括模型幻觉(草莓里的r有多少个?)6]), 不自动鉴别(模型无法判断它们是否正确地完成了任务 [7诸如安全漏洞等问题。
当我们考虑到伦理问题时,情况并没有好转。AI 开启了一系列复杂的问题:版权、隐私、环境和经济问题。简要总结一下,为了避免超出本文的篇幅:
AI是用被盗的数据训练的:用于训练的大多数内容如果不是绝大多数都是被盗。在我们的社会正审视著作权保护和合理使用界限的过程中,由IA引发的恐慌可能与其本身的侵权行为造成同样的损害。史密森尼学会8], 大西洋杂志 [9], IBM [10], 和自然 [11大家都在谈论它。
经济不平等的延续:代理,首席执行官通常通过大规模裁员、降低工资或更糟糕的工作条件来应对他们所做的一些规模大且回报低的投资。这加剧了社会和经济的不平等,并仅服务于维持人工智能泡沫的目的。12].
贡献于环境危机: 地球的研究13],声称ChatGPT-3(1750亿参数)的训练过程中使用了70万升淡水,并且每次与用户的平均对话消耗半升水。线性外推该研究,对于ChatGPT-4(大约1.8万亿参数),训练过程将耗用700万升水,每次对话则会消耗5升水。
最近的一项研究由马克西姆·洛特 [14], 标题( sic )“人工智能重大突破:OpenAI通过了智商120测试 ” [15他在拥有6000多名订阅者的通讯newsletter中发布的内容显示,在用智商测试评估AI时取得了令人鼓舞的结果。新的OpenAI o1取得了120的智商分数,与其后的模型(Claude-3 Opus、GPT-4 Omni和Claude-3.5 Sonnet,各自得分略高于90智商)之间存在着巨大的差距。
这些是七项智商测试的平均结果。作为背景信息,一个120的智商意味着OpenAI在人类智力水平中处于前10%。
有什么陷阱?这就是全部吗?我们已经编程出一个(特别)比普通人聪明的模型了吗?机器已经超过它的创造者了吗?
问题在于,一如既往地,训练集马克西姆·洛特声称 rằng测试题不在训练集里或者至少说,他们是否在里面无关紧要15值得注意的是当他用一个据称是私有的、未发表的(但经过校准的)测试来评估这些模型时,智商分数被彻底摧毁了。:
这为什么会发生?
这是发生的原因是模型在其训练数据集中包含这些信息通过搜索他们被问到的问题,他们能够得到结果而无需“思考”这些问题。
想想看,在考试之前,一个人被给了所有的问题和答案,只需要记住每一道题的答案。他们拿到满分也不能说他们是聪明的,对吧?
除此之外,在这两项测试中,视觉模型的表现非常糟糕,计算出的智商在50到67之间。他们的得分与随机作答的代理一致在Mensa挪威的测试中,这将导致每六道题中有一道是正确的。根据M. Lott的观察以及实际测试如WAIS-IV的工作方式,如果25/35相当于智商120,那么17.5/35相当于智商100,9/35略高于80智商,而随机选择(约6/35正确)将得分大约在69至70智商之间。
不仅如此,大多数问题的推理似乎最多也只是严重偏离事实或干脆就是错误的。模型似乎在寻找不存在的模式,或者生成预先写好的、重复使用的答案来为其选择进行辩护。
此外,在声称测试仅限离线进行的同时,似乎该测试被在线发布了一段时间。 quoted as, “““quoted as”””部分似乎是原文中的一部分,如果不需要翻译这部分,则保留原样。如果是引语的开始标记,请提供完整的句子以便准确翻译。然后我创建了一个包含他新问题的调查问卷,并加入了一些挪威门萨的问题,邀请这篇博客的读者参与。大约有四十位读者参加了。然后我删除了调查问卷这样,这些问题从未被发布到可以通过搜索引擎等访问的公共互联网上,因此它们应该不会出现在AI训练数据中。.“ [15].
作者不断自相矛盾,提出缺乏实际证据的支持的模糊说法,并将其当作真实证据。
所以不仅这些问题被发布到了互联网上,而且考试中还包含了以往的老题。(那些)训练数据中出现的我们在这里再次看到洛特自相矛盾的陈述。
遗憾的是,我们没有详细的问题结果或比例的分解,也无法将其区分为旧问题和新问题。看到这些结果肯定会很有趣。再次表明研究是不完整的。
所以确实有证据表明这些问题出现在训练数据中,并且这些模型并没有真正理解它们在做什么或它们自己的“思考”过程。
更多示例可以在其中找到这个关于AI和创意生成的文章。尽管它也跟上了炒作的浪潮,但它展示了模型无法区分好坏想法,暗示它们不了解其任务背后的概念。7].
结果有什么问题?
根据科学方法,如果一名研究人员得到了这样的结果,下一步的逻辑做法是接受OpenAI拥有不没有取得任何重大突破(或者即使取得了突破,也无法通过智商测试衡量出来)。相反,洛特坚持他所说的“人工智能的重大突破”的叙事。这是误导信息的开始。
让我们来总结一下:这些文章是如何推动人工智能泡沫的?
文章的SEO16这非常聪明。标题和缩略图都非常具有误导性,进而使得推特、Instagram和LinkedIn上的帖子看起来很吸引人。IQ曲线图上惊人的得分实在是无法忽视。
在本节中,我将回顾一些关于“新闻片段”如何通过社交媒体传播的例子。请留意嵌入的推文可能需要几秒钟加载。
这条推文声称结果是“根据挪威门萨智商测试”,这是不真实的。这些说法并非由该测试提出,而是由第三方提出的。再次强调,它将其表述为事实,后来却给出了可能的否认理由(“如果属实则是疯狂的”)。让我们来看下一个例子:
这条推特直接呈现了Lott的研究,并将其当作事实(“人工智能现在比普通人更聪明”)。除此之外,只向读者展示了一个图表的截图(训练数据中的问题和答案、被夸大的分数),这极具误导性。
这显然是误导性的。即使有所声明,信息仍然是不正确的。后一次测试并未做到无污染,因为它据称包含了一些在线可获取的题目,并且在视觉部分的表现仍然非常差。这里没有可以观察到的趋势。
反复核查我们分享的信息是非常重要的。虽然真相是一个不可达到的绝对,但虚假或部分虚假的信息是真实存在的。不应让炒作、泛化的社会情绪或其他类似力量驱使我们在没有充分核实的情况下随意发布信息,从而无意中维持了一个本应多年前就消亡的运动,并且这个运动正在产生如此负面的经济和社会影响。
越来越多原本应该局限于情感和理念领域的事情正在影响我们的市场,股市每天变得更加动荡。人工智能繁荣的例子只是炒作和错误信息如何结合以及它们可能产生多么灾难性后果的一个例子。
免责声明:如以往一样,回复开放进一步讨论,欢迎大家参与。任何形式的骚扰以及针对原帖作者、第三方或我的仇恨言论都不会被容忍。任何形式的其他讨论都是欢迎的,无论是建设性的还是尖锐的批评。研究应该始终能够被质疑和审查。
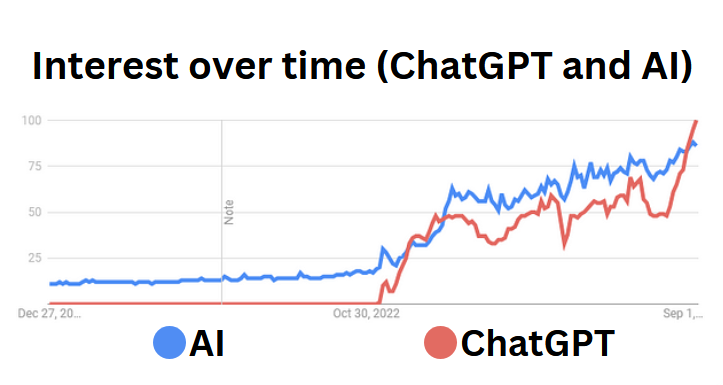
Google Trends,自2021年以来的“AI”和“ChatGPT”搜索可视化。https://trends.google.com/trends/explore?date=2021-01-01%202024-10-03&q=AI,ChatGPT&hl=en
[2] IBM于2023年关于CEO们及其在商业决策中看待和使用AI的研究。https://newsroom.ibm.com/2023-06-27-IBM研究:首席执行官拥抱生成式AI,生产力成为其首要议程事项
[3] CNN,科技公司裁员中的AI因素。https://edition.cnn.com/2023/07/04/tech/ai-tech-layoffs/index.html
[4] CNN,裁员和在人工智能方面的投资。https://edition.cnn.com/2024/01/13/tech/tech-layoffs-ai-investment/index.html
[5] 彭博社,AI导致的裁员比公司愿意承认的要多。https://www.bloomberg.com/news/articles/2024-02-08/人工智能导致的裁员数量比公司愿意承认的要多
[6] 苹果公司,一个草莓里有多少rs?这个AI无法告诉你https://www.inc.com/kit-eaton/草莓中有多少个r?这个AI无法告诉你.html
[7] arXiv,LLM能否生成新颖的研究想法?一项涉及100多名自然语言处理研究人员的大规模人类研究。https://arxiv.org/abs/2409.04109
[8] 史密森尼学会,AI图像生成器是否在抄袭艺术家的作品?https://www.smithsonianmag.com/smart-news/人工智能图像生成器是否在侵犯艺术家的权利-180981488/
[9] 大西洋月刊,生成式AI无法引用其来源。https://www.theatlantic.com/technology/archive/2024/06/chatgpt-citations-rag/678796/
IBM,关于人工智能隐私的话题https://www.ibm.com/think/topics/ai-隐私
[11] 自然、知识产权和数据隐私:AI隐藏的风险。https://www.nature.com/articles/d41586-024-02838-z
施普林格,人工智能炒作的机制及其对地球和社会的成本。https://link.springer.com/article/10.1007/s43681-024-00461-2
[13] 地球,ChatGPT-3 的环境影响https://earth.org/环境影响_chatgpt/
[Twitter, 用户“maximlott”.]https://x.com/maximlott
Substack,人工智能的重大突破:OpenAI通过了智商120的测试。https://substack.com/home/post/p-148891210
[16] Moz,什么是SEO?https://moz.com/learn/seo/什么是SEO
泰国科技创新,科技公司,AI幻觉示例https://www.thairath.co.th/money/tech_innovation/tech_companies/2814211
[Twitter, 推文 1]https://x.com/rowancheung/status/1835529620508016823
[Twitter, 推文 2]https://x.com/Greenbaumly/status/1837568393962025167
[20] Twitter,推文3https://x.com/AISafetyMemes/status/1835339785419751496