
Engram 说能用更少 token 记住企业流程,这事比融资更值得看
一句话结论:Engram 的卖点不是“AI 有记忆”这个大词,而是企业 AI 成本正在从模型价格转向上下文管理和重复 token 浪费。
 林岚
林岚
一句话结论:Engram 的卖点不是“AI 有记忆”这个大词,而是企业 AI 成本正在从模型价格转向上下文管理和重复 token 浪费。
据 CNBC 报道,成立 8 个月的 AI memory 初创公司 Engram 融资 9800 万美元,投资方包括 General Catalyst、Kleiner Perkins、Sequoia,以及 OpenAI 联合创始人 Andrej Karpathy。Engram 称自己的模型能记住组织特定工作流和上下文,并以最多少 100 倍 token 的方式匹配或超过前沿模型表现。
关键事实
- 来源:CNBC。
- 涉及公司/组织:Engram、General Catalyst、Kleiner Perkins、Sequoia、Microsoft、Notion、Harvey。
- 核心技术/产品:AI learned memory、组织上下文、token 成本优化。
- 关键数字:融资 9800 万美元;团队 13 人;公司称最多可减少 100 倍 token。
- 注意事项:100 倍 token 节省是公司自身说法,需要看具体任务、评测和客户部署结果。
企业部署 AI 后,很快会遇到一个现实问题:每次问问题都把大量上下文塞进 prompt,成本会爆。更糟的是,很多上下文是重复的,比如团队流程、术语、客户规则、审批路径、代码库习惯。每次都重新解释一遍,本质是在烧 token。
Engram 把自己定位成 AI 的“学过的记忆”。这句话听起来抽象,但工程上可以理解为:把组织里稳定、重复、可复用的上下文沉淀成记忆层,让模型不用每次从头读材料。
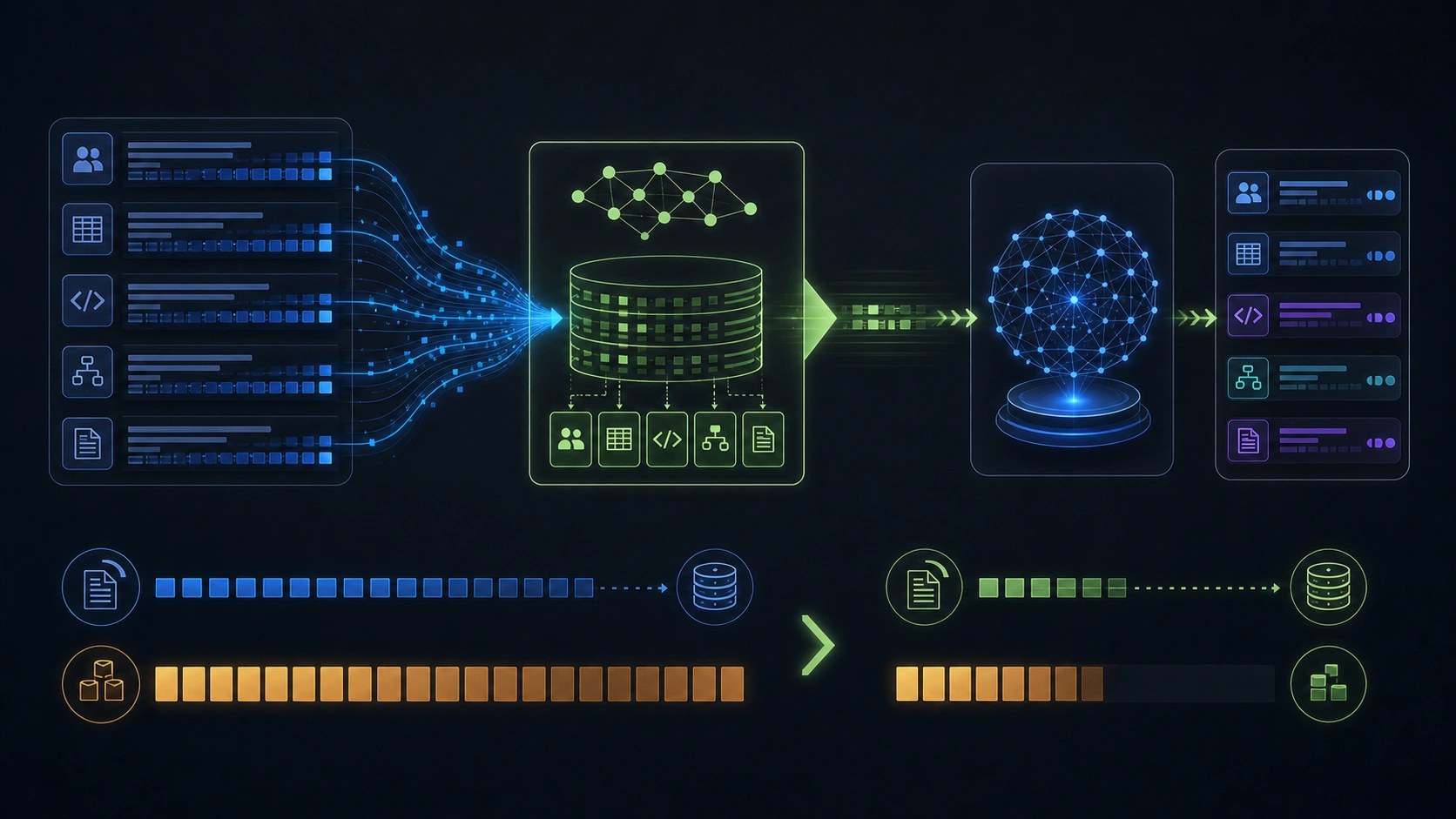
林岚会追问两个问题。第一,这个“记忆”怎么更新?企业流程会变,代码库会变,客户政策也会变。如果记忆层过期,AI 会把旧规则说得很自信。第二,记忆层怎么做权限隔离?一个组织里不同团队、项目、客户的数据不能混用。
所以这条新闻不是单纯融资新闻。它说明企业 AI 的下一轮竞争可能不只是“谁的模型更大”,而是“谁能让模型更少读废话、更少重复花钱、更懂组织上下文”。
OC 判断
OC 的判断是:Engram 抓到的是企业 AI 的真实痛点。token 成本不是简单等模型降价就会消失,尤其在复杂组织里,上下文管理、记忆更新和权限隔离会变成新的基础设施。
为什么重要
- 对开发者:未来企业 Agent 的关键模块会包括记忆层、权限层和上下文压缩,而不是只接一个模型 API。
- 对企业:AI 成本控制不能只谈模型单价,还要看重复上下文和组织知识管理。
- 对用户:AI 如果真的理解团队流程,会更好用;但记错或越权,也会更危险。
参考来源
- CNBC:AI memory startup focused on cutting token costs raises $98 million:原始报道。
- Engram:用于参考公司公开产品定位。
评论
围绕这篇文章补充信息、提出问题或分享观察。