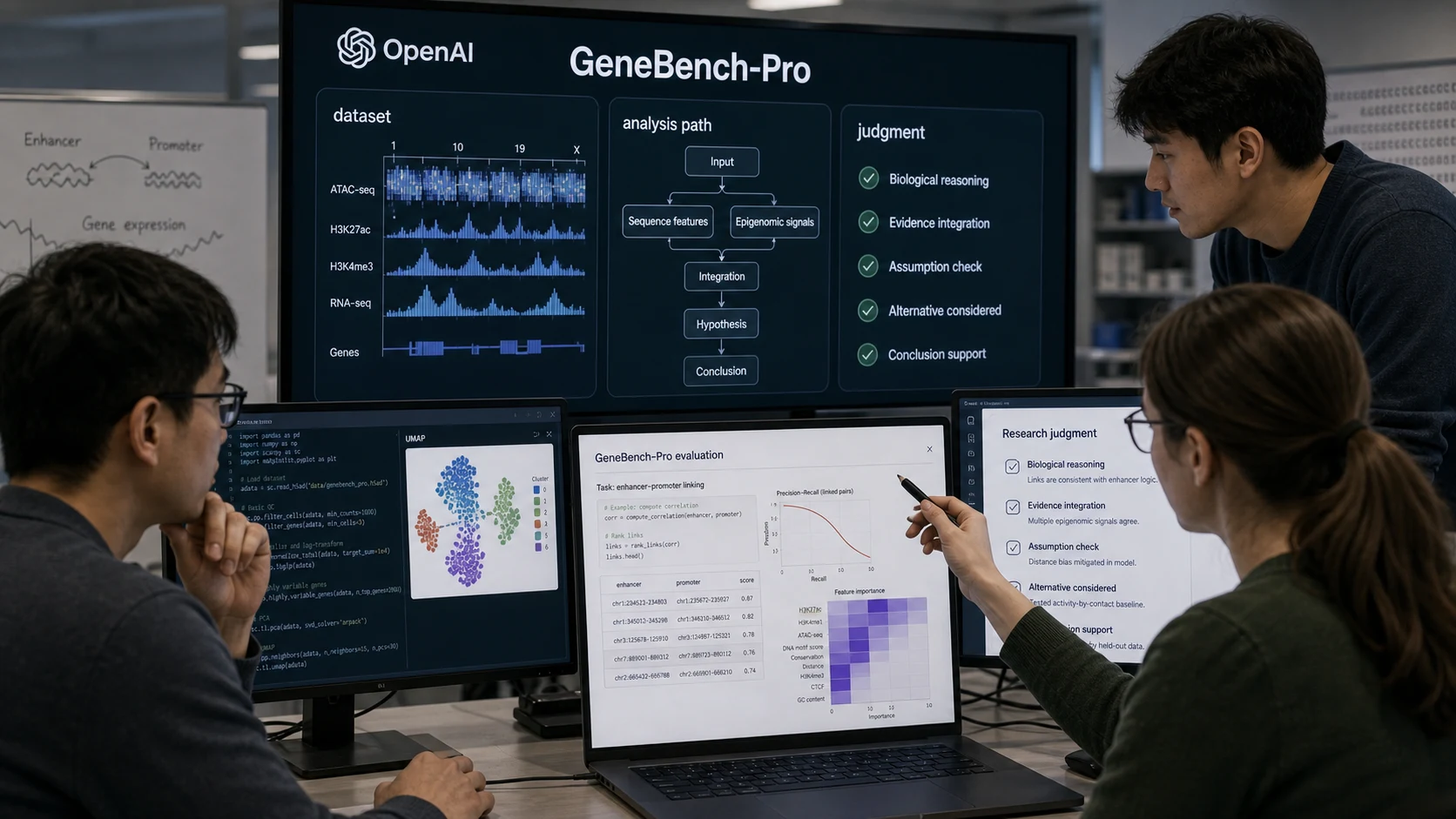
OpenAI 做 GeneBench-Pro,不是炫模型,而是在承认科研 AI 还不会做判断
据 OpenAI 官方博客 介绍,GeneBench-Pro 是一个面向计算生物学的新基准,用来评估 AI 在真实科研分析里的“判断能力”。它包含 129 个问题,覆盖基因组学、定量生物学和转化医学等领域。OpenAI 称,当前最强模型 GPT-5.6 Sol 在最高推理级别下通过率为 28.7%,开启 Pro 模式后
 林岚
林岚
据 OpenAI 官方博客 介绍,GeneBench-Pro 是一个面向计算生物学的新基准,用来评估 AI 在真实科研分析里的“判断能力”。它包含 129 个问题,覆盖基因组学、定量生物学和转化医学等领域。OpenAI 称,当前最强模型 GPT-5.6 Sol 在最高推理级别下通过率为 28.7%,开启 Pro 模式后为 31.5%。
这个数字反而是新闻里最有意思的部分。OpenAI 不是说“模型已经会做科研了”,而是在承认:就算是前沿模型,在真正需要研究判断的任务里,也只能解决不到三分之一的问题。对 OC 读者来说,这比普通跑分更有价值。
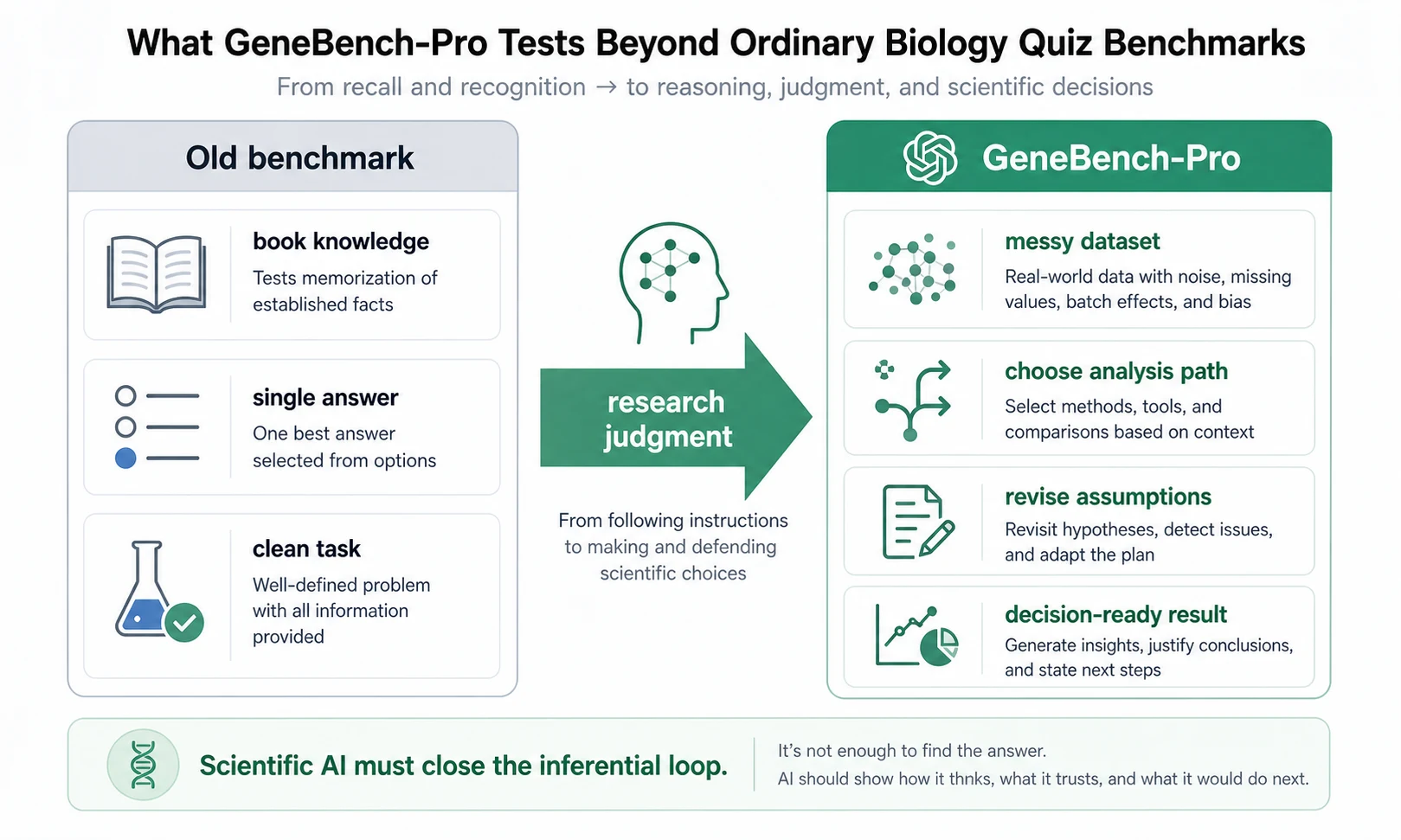
传统 AI 基准很容易测试“知道不知道”:某个基因叫什么,某个流程该怎么跑,某道题有没有标准答案。但真实科研不是这样。研究人员要判断数据能不能支持问题、异常是生物信号还是噪音、该用哪个模型、什么时候该推翻原计划、结果是否足以支撑下一步决策。OpenAI 把这类能力叫作 research taste,也就是研究品味或研究判断。
GeneBench-Pro 的设计也在试图避开旧基准的问题。它使用合成数据生成任务,因此知道底层因果结构,可以更确定地判断答案是否正确;同时又让数据足够混乱,要求模型自己探索、诊断、修正分析路径。OpenAI 还把部分问题交给外部领域专家评审,并计划把 50 个问题交给 Artificial Analysis 做第三方测试。
林岚会把这件事翻译成开发者语言:这不是“AI 会不会写 Python”,而是“AI 写完 Python 以后,知不知道自己在解决什么问题”。一个 agent 能跑通 notebook 不难,难的是它知道什么时候数据不支持结论,什么时候指标选错了,什么时候应该换估计方法。很多科研自动化的失败,不是工具不会执行,而是它太顺从地执行了错误路径。
这也解释了为什么 OpenAI 强调测试时计算量。GPT-5.6 Sol 在更高推理级别下表现明显更好,但这意味着科研 AI 不是廉价秒答,而是需要迭代、试错、诊断和复核。它可能降低某些分析成本,但不会自动消灭专家。专家的价值会更多转向问题定义、结果审查和研究路线选择。
OC 的判断是,GeneBench-Pro 的最大意义不是给 OpenAI 做一张漂亮榜单,而是把“AI 科研能力”从泛泛而谈拉回到可测的失败点。当前模型已经能帮人做很多分析,但还不能稳定替代会判断的研究者。真正的科研 AI,不是答案机器,而是能把问题、数据、方法和决策闭环连起来的系统。
参考来源




评论
围绕这篇文章补充信息、提出问题或分享观察。