
微服务的疑问
论坛潜水了许久,最近有个疑问,感觉实在搞不定,不得已,望指点~
最近公司的项目用微服务的形式挑了一下,总感觉不对头,希望大家帮忙解答一下,能给个大概的模块拆分标准,库表拆分原则,或者是参考资料、书籍之类的东西~情况大致如下
最开始,我们的系统就是一个简单的 tomcat 应用

然后客户反应不错,直接代码复制,稍做修改,为新客户部署了第二套

接着就发现,代码雷同度太高,相同的BUG 需要修改俩个地方,这样下去不行,于是抽离了其中的核心部分,将硬件设备统一管理,用户只需要关注业务,同时将各个服务独立开来,并且接入更多的客户
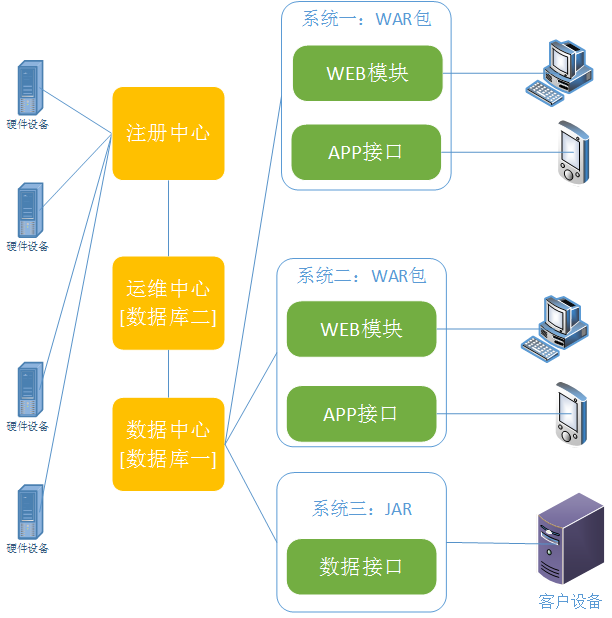
在第三个阶段,就发现业务逻辑开始有点乱了,用户直接查询自己的数据没问题,但是如果希望获取到当前设备的状态,就需要去运维中心查,这样通过数据中心中转了一次,一个设备 ID,两个库表都要存一份,类似这样
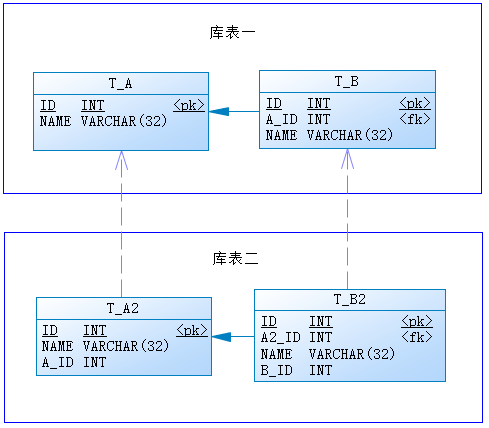
这样看起来,感觉就不对~
你这是微服务?用的不是netflix那套技术栈吧
调用链不长的话,可以在服务内部用feign走rest调用获取数据,如果太长不想做feign也可以用rpc或者缓存。不同服务直接的表,原则上是不建议做表关联的。服务A用MySQL, 服务B用Oracle,服务C用Mongodb都有可能,所以设计上尽量避免耦合,冗余一些没啥。
目前 WEB app server 的数据基本都是本地库表读写 + 接口调用,只是感觉接口的设计没有统一,时间都赶,想到啥做啥,先上了再说,感觉就比较乱。
用的是 dubbox。最后一张图中,两个库之间没有外键关联,只是库表一中的主键写入到了库表二当中,这样如果交互的业务实体多了,感觉冗余字段越来越多,数据更新时涉及到服务之间的数据库事务同步也多,没有在框架中增加分布式事务的功能。微服务这块,有没有比较好的设计资料或书籍可以参考的?摸石头过河,感觉留了好多坑~
另外,问一个细节上的问题
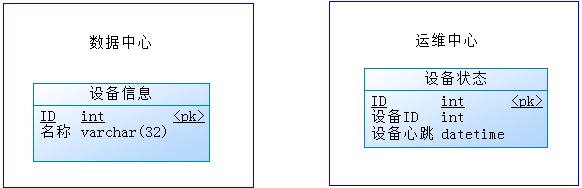
比如,原来设计是【运维中心】储存设备的心跳时间,现在系统一要查询属于它的设备信息。
这时,直接在【数据中心】进行分页查询出10条数据后,发现还缺少心跳信息,就通过接口去【运维中心】查询,接口的传参就是10个 id 编号,返回值是每个 ID 对应的心跳时间,可能是一个类似这样的接口
Map<Long, Date> heartbeatTimes(Set<Long> ids);
获取到心跳之后,要把心跳数据拼接回原来的10条记录当中,相当繁琐的感觉~ 换个思路,在每次更新心跳的时候,数据中心的设备信息中,也冗余一个心跳字段,这样,业务一多,冗余字段也多,感觉也不是很好~