

2025 年 ARC 奖结果与分析
作者:By Mike Knoop
细化循环之年
我们已经正式结束了 ARC 奖第二年的评选!虽然大奖仍未有人领取,但我们很高兴地宣布2025 年 ARC 奖得分和论文获奖者并分享基于ARC-AGI的2025年AGI进展新分析。

比赛进展
首先是Kaggle比赛的成绩。总共,1,455 支队伍提交了 15,154 份参赛作品2025 年 ARC 奖 - 与 2024 年 ARC 奖几乎相同。Kaggle 得分最高的获胜者在 ARC-AGI-2 私人数据集上达到了 24% 的新 SOTA,每任务 0.20 美元。
我们还提交了 90 篇论文,高于去年的 47 篇,其中许多论文的质量都非常出色!由于论文质量卓越,我们决定扩大论文奖项范围,新增 5 名亚军,并表彰 8 名额外荣誉奖。
我们很自豪地说:所有 ARC 奖 2025 获奖解决方案和论文都是开源的。
行业进展
我们已经看到 2025 年 ARC-AGI-2 从商业前沿人工智能系统和定制模型细化解决方案中取得了实质性进展。截至今天,经过验证的最佳商业模型 Opus 4.5(Thinking,64k)的得分为 37.6%,每任务 2.20 美元。经验证的顶级优化解决方案基于 Gemini 3 Pro 构建,由 Poetiq 编写,每任务 30 美元,得分为 54%。
过去一年,ARC-AGI 已被四大 AI 实验室在模型卡上报道,以对标前沿 AI 推理:开放人工智能,xAI,人择, 和谷歌深度思维。
2024 年,ARC-AGI 基准精确定位的的到来《人工智能推理系统》并推动了早期的解释性分析。我们部署人工智能推理系统才一年,我们认为这项新技术与法学硕士的发明不相上下。ARC 帮助我们了解了扩展这一新范式的能力和速度。
现在到了 2025 年,ARC-AGI 正在被用来演示“细化循环”。从信息论的角度来看,精益求精就是智慧。虽然我们仍然需要新的想法来实现 AGI,但 ARC 已经催生了几种现已开源的改进方法(记录如下)。我预计这些将在 2026 年进一步推动人工智能推理。
现在,让我们来认识一下今年竞赛进步奖的获得者。
2025 年 ARC 奖获奖者
高分
| 地点 | 奖品 | 团队 | ARC-AGI-2 私人评估分数 | 来源 |
|---|---|---|---|---|
| 第一名 | 2.5 万美元 | NVARC | 24.03% | 代码|纸|视频 |
| 第二名 | 1万美元 | 建筑师 | 16.53% | 代码|纸|视频 |
| 第三名 | 5000 美元 | 思维人工智能 | 12.64% | 代码|纸|写作|视频 |
| 第四名 | 5000 美元 | 朗尼 | 6.67% | 代码|纸 |
| 第五名 | 5000 美元 | G·巴巴迪罗 | 6.53% | 代码|纸 |
论文奖
| 地点 | 奖品 | 作者 | 标题 |
|---|---|---|---|
| 第一名 | 5万美元 | A.若利科-马蒂诺 | 少即是多:微型网络的递归推理(纸,采访) |
| 第二名 | 2万美元 | J. Pourcel、C. Colas 和 P. Oudeyer | 用于进化程序综合的自我改进语言模型:ARC-AGI 案例研究 (纸,视频) |
| 第三名 | 5000 美元 | 廖一、顾阿 | 没有预训练的 ARC-AGI (纸,视频) |
| 亚军 | 2500 美元 | I. Joffe & C. Eliasmith | 抽象和推理语料库的向量符号代数 (纸) |
| 亚军 | 2500 美元 | J·伯曼 | 从鹦鹉到冯·诺依曼:进化测试时计算如何在 ARC-AGI 上实现最先进的 (纸) |
| 亚军 | 2500 美元 | 彭毅 | 高效的进化程序合成(纸) |
| 亚军 | 2500 美元 | E. Guichard、F. Reimers、M. Kvalsund、M. Lepper&d 和 S. Nichele | ARC-NCA:走向抽象和推理语料库的发展解决方案(纸) |
| 亚军 | 2500 美元 | M.Ho等人。 | ArcMemo:具有终身 LLM 记忆的抽象推理作文(纸) |
荣誉提名
| 作者 | 标题 |
|---|---|
| K.胡等人。 | ARC-AGI 是一个视力问题!(纸) |
| D. 弗兰岑、J. 迪塞尔霍夫和 D. 哈特曼 | 法学硕士专家的成果:提升 ARC 性能是一个视角问题(纸,采访) |
| G·巴巴迪罗 | 探索搜索和学习的结合来应对 ARC25 挑战(纸) |
| A. Das、O. Ghugarkar、V. Bhat 和 J. McAuley | 超越暴力:ARC-AGI-2 中用于组合推理的神经符号架构(纸) |
| R·麦戈文 | 小型递归模型的测试时适应(纸) |
| P.Acuaviva 等人。 | 重新思考视觉智能:视频预训练的见解(纸) |
| J.科尔和M.奥斯曼 | 不要把孩子和洗澡水一起倒掉:ARC 深度学习的方式和原因(纸,采访) |
| I. 索罗金和让-弗朗索瓦·普吉特 | ARC-AGI-2 2025 的 NVARC 解决方案(纸) |
细化循环
2025 年推动 AGI 进步的中心主题是细化循环。其核心是,细化循环迭代地将一个程序转换为另一个程序,其目标是根据反馈信号逐步优化程序以实现目标。
两个例子来自进化测试时计算(J. Berman)和进化程序综合(E. Pang)。Berman 的方法推动了进化搜索工具以自然语言发展 ARC 解决方案。Pang 的方法也是如此,但使用的是 Python,并动态创建程序抽象库来引导综合。
在这两种情况下,这些方法都会经历一个两阶段的细化过程。首先,它探索(生成许多候选解决方案),然后验证(分析程序以产生反馈信号)。每个任务都会循环重复此操作,直到最终生成的程序得到充分改进并为所有训练输入/输出对提供准确的答案。
零预训练深度学习方法
细化循环正在成为新型深度学习模型训练的基础。
传统上,深度学习模型使用梯度下降对输入/输出对进行训练,以创建静态神经网络。这种训练算法逐渐细化网络潜在空间中的高维曲线。然后在推理时,当出现新输入时,网络会进行前向传播,以沿着该曲线近似输出。这一基本概念,再加上测试时适应和数据增强,使得 2024 年 ARC 奖获得最高分(建筑师)和 2025 年(NVARC)。
我们现在看到了一种非常不同的训练方法的早期成功,该方法直接训练神经权重来表示任务解决程序。输入/输出对仍然用作基本事实,而细化循环在训练、镜像程序综合方法中发挥着关键作用,但这次是在权重空间中。
这种方法有两个不寻常的特性:
- 由此产生的网络相对 ARC-AGI 性能来说非常小。
- 所有材料特定任务培训都在测试时进行。
开源示例
微型递归模型 (TRM)微型递归模型 (TRM)
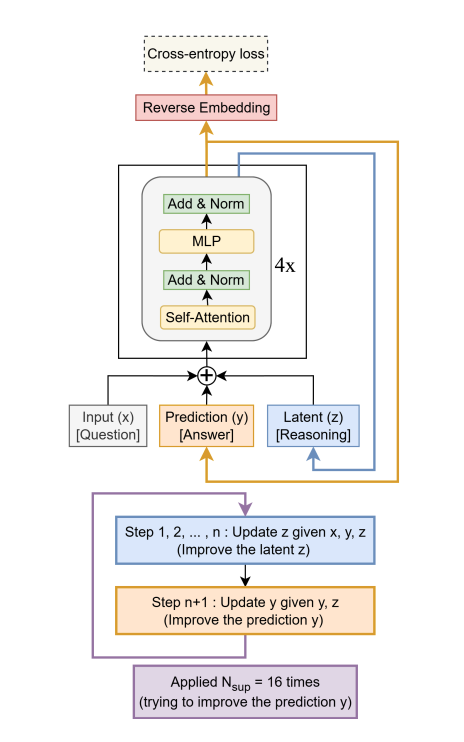
来自论文:
TRM 递归地改进其预测答案y
通过一个微小的网络。它从嵌入的输入问题开始x和初始嵌入答案y,和潜伏的z。对于高达Nsup = 16改进步骤,它尝试改进其答案y。它通过 i) 递归更新来实现n倍其潜伏z鉴于问题x,当前答案y,以及当前潜在的z(递归推理),然后 ii)更新其答案y给出当前答案y和目前的潜伏期z。这种递归过程允许模型以参数极其高效的方式逐步改进其答案(可能解决先前答案中的任何错误),同时最大限度地减少过度拟合。压缩ARC
压缩ARC
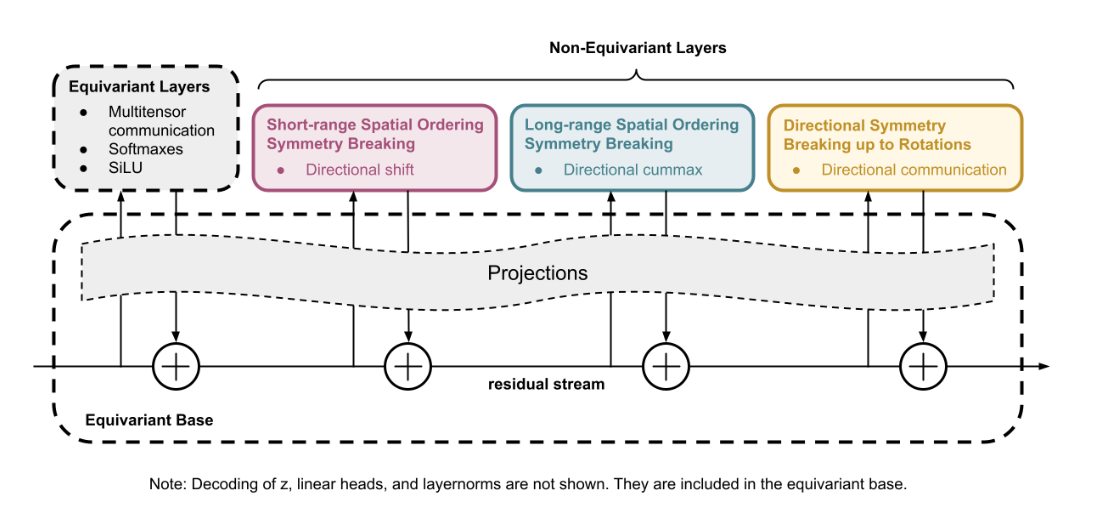
该解决方案具有以下特点:
没有预训练。
- 模型是随机初始化和测试时训练的。
- 没有数据集。一种模型仅针对一项目标任务进行训练并输出一个答案。
- 没有分支搜索。只是梯度下降。
该方法的工作原理是在测试时最小化每个任务的描述长度(MDL 原则)。Liao 推导了如何使用带有解码器正则化的典型变分自动编码器 (VAE) 损失来代替组合搜索来细化非常小的神经网络程序。如此小的网络的泛化结果令人印象深刻。
商业示例
我们还有商业人工智能推理系统迭代“细化”的证据。思想链可以解释为将一种潜在状态转换为另一种潜在状态的自然语言程序。
考虑 ARC-AGI 任务#4cd1b7b2。Gemini 3 Pro 使用了 96 个推理标记来解决问题,而 Gemini 3 Deep Think 则使用了 138,000 个推理标记。这些系统的更高推理模式与更多推理标记(更长的程序)密切相关,即使不是严格需要的。
这些较长的自然语言程序允许更多的细化(进一步的探索和验证)。
以下是我们在实践中看到的一些推理分析输出的示例。
……不符合完整的要求。这表明当前的解决方案可能无法完全满足谜题的限制。我需要重新检查盒子配置并探索替代安排…(Claude Opus 4.5)
……这表明需要进一步调查才能完成分析。我将验证第 9 行第 15 列的中心点…(Claude Opus 4.5)
……也许每个输入行在输出中都被重复了三遍,但这与其余行如何匹配呢?等等,第三个输出行是 � (QwQ 32B)
2025 年末发布的前沿商业模型(Gemini 3、Claude Opus 4.5,……)的一项新的重要发现是,您可以在应用程序层添加细化循环,以有意义地提高任务可靠性,而不是仅仅依赖提供者推理系统。这仍然需要基础模型具有任务领域的知识覆盖范围。
模型改进
我们在排行榜中添加了一个新类别,名为模型改进并验证了新的 Gemini 3 Pro 改进,由 Poetiq 开源,这将 ARC-AGI-2 的性能从基线 31%(每任务 0.81 美元)提高到 54%(每任务 31 美元)。值得注意的是,据报道,相同的模型改进在 Claude Opus 4.5 上实现了类似的改进,其准确度可与 Gemini 3 Pro(参考)相媲美,但每个任务的成本大约是 Gemini 3 Pro 的两倍(约 60 美元/任务)。诗学。
目前,我们看到的优化工具是特定于领域的。但借助 GEPA 和 DSPy 等技术,人们可以在应用层开发通用可靠性改进(只要您有一个能够产生反馈信号的验证器或环境)。
我们期望这些类型的总体改进和利用改进最终能够在商业人工智能系统的“API 背后”发挥作用。我们还预计,前沿的、特定于任务的准确性将继续由应用层的知识专业化和验证者驱动。
AGI 的进展与 ARC 的未来
截至 2025 年,随着人工智能推理系统的出现,具有以下两个特征的任务领域可以可靠地实现自动化——无需新的科学。
- 基础模型中有足够的任务知识覆盖
- 任务提供可验证的反馈信号
当前的人工智能推理性能与模型知识相关。
我们应该花点时间来体会一下这是多么奇怪!人类的推理能力并不局限于知识,这会产生各种奇怪的含义,并导致我们做出“锯齿状智力”等不精确的类比。
今年有很多支持证据,包括 ARC-AGI-2(静态抽象推理)、2025 年 IMO Gold(数学)和 2025 年 ICPC 100%(编码)的分数——所有这些都是由人工智能推理系统取得进展的。这些任务领域比纯法学硕士有用的狭窄任务领域要广泛得多。但是,从全球意义上来说,它们仍然相对狭窄。
尽管如此,这是今年出现的人工智能能力的深刻升级。思想链综合的发明和规模化可以与变压器的发明和规模化相媲美。但我们现在还很早。很少有人直接体验过这些工具。根据 OpenAI,只有约 10% 的 ChatGPT 免费用户曾经使用过“思考”模式。我预计当前技术的传播(即使只是在商业领域)还需要 5 到 10 年的时间。
收集领域知识和构建验证器并不是免费的。这是一项相对昂贵且专业的工作。目前,人工智能自动化取决于社会投资所需人才、计算和数据的意愿。我预计在未来 12-24 个月内,随着社会对哪些问题(1)最重要和(2)适合成本阈值进行全球搜索,将会出现令人兴奋的新结果。
这包括人工智能系统在知识覆盖范围广的领域产生新科学知识的早期成果。就在这周,Steve Hsu 发表了一个使用生成器验证器的人工智能细化循环示例,以创建量子物理学中的新颖结果。
然而,许多(如果不是大多数)潜在的自动化问题都超出了当今社会成本的承受范围。随着工程的进展,成本将会下降,从而为自动化开辟更多领域。从更大的角度来看,能够进行高效适应以产生范式转变创新的机器仍然完全属于科幻小说的范畴。
对于 ARC-AGI-1/2 格式,我们认为大奖精度差距现在主要受到工程的瓶颈,而效率差距仍然受到科学和想法的瓶颈。ARC 奖代表开放 AGI 进步,正如我们之前承诺的那样,我们将在 2026 年继续举办 ARC-AGI-2 大奖竞赛,以跟踪完全开放和可复制解决方案的进展情况。
尽管人工智能推理系统非常出色,但它们仍然存在许多通用人工智能所必需的缺陷和低效率。我们仍然需要新的想法,比如如何分离知识和推理等等。我们需要新的基准来突出这些新想法的出现。
知识过度拟合
机器学习中有一个概念叫做过拟合。传统上,当你的模型学习时就会发生这种情况太多了来自训练。它学会记住确切的数据,而不是学习一般模式。这导致模型在测试时对看不见的数据表现不佳。
出于这个问题,一个常见的人工智能基准测试批评是,模型提供商被激励去“基准最大化”或通过“训练测试”来作弊,以报告营销基准的高分,而这些基准不能推广到现实世界的用例。
ARC-AGI-1 和 ARC-AGI-2 旨在通过使用私人数据集进行官方评分和验证来抵抗这种类型的过度拟合。
人工智能推理系统以反映真正进步的方式改变了游戏。当基础模型扎根于更广泛的领域时,他们表现出了非零的流体智能,并且能够适应远离其确切知识的任务。
这意味着,如果公共训练和私人测试集太相似(例如,国际直拨电话)并且该模型是根据大量公共领域数据进行训练的。
我们相信这种情况正在 ARC-AGI-1 和 ARC-AGI-2 上发生——我们无法判断是偶然还是有意。
我们的一点证据双子座3验证:
▪ 目标是绿色 (3)。图案为洋红色 (6) 纯色。结果:绿色上的洋红色方块 � (Gemini 3 Deep Think)
我们的 LLM 验证工具没有提及 ARC 任务或颜色格式,但该模型在其推理中使用(正确!)ARC 颜色映射。这强烈表明 ARC 数据在底层模型中得到了很好的表示,足以仅基于 2D JSON 整数数组的结构和格式做出正确的 ARC 推断。
新元
虽然我们相信这种新型的“过度拟合”正在帮助模型解决 ARC,但我们并不确定具体有多少。无论如何,ARC-AGI-1 和 ARC-AGI-2 格式为人工智能推理进展提供了有用的科学金丝雀。但基准的设计未来需要进行调整。
事实上,过去两年 ARC 奖给了我一个更广泛的教训:最有趣和最有用的基准是由从根本上渴望推动进步的团队创建的。
为了推动进步,您必须通过认真研究来理解底层技术。你必须愿意引起人们对缺陷的注意并激励采取行动。随着技术的进步,你必须适应。而且你必须年复一年地这样做。建立伟大的基准需要持续的努力。
关键词是适应。适应是智力的核心模式。这个过程不仅仅是创建伟大的基准,它还是通用智能本身的最终衡量标准。
来自弗朗索瓦·乔莱,去年12月:
当创建对普通人来说很容易但对人工智能来说很难的任务变得根本不可能时,你就会知道 AGI 已经出现了。
ARC-AGI 手册:通过迭代改进基准来运行细化循环,以响应人工智能的进步,从而将“对人类来说容易,对人工智能来说困难”之间的差距缩小到零。
那么,我们有AGI吗?还没有。我们正在努力准备 ARC-AGI-3 于明年初发布,并且对新格式感到非常兴奋,我们认为这需要新的想法!ARC-AGI-3
在内部,我们完全专注于开发 ARC-AGI-3
过去 6 个月。与 ARC 的所有版本一样,它的设计目标是“对人类来说容易,对人工智能来说困难”,同时也是指向 AGI(以及我们仍然缺少解锁它的东西)的最有趣和科学上有用的基准。我们正在开发数百款前所未见的游戏。

我们计划于 2026 年初与 ARC Priest 2026 一起发布 ARC-AGI-3。这个新版本标志着自 2019 年推出 ARC 以来的首次重大格式更改。前 2 个版本挑战静态推理,而第 3 版旨在挑战交互式推理,需要新的 AI 功能才能成功。
- 探索
- 规划
- 内存
- 目标获取
- 对准
我们早期的人体测试和人工智能研究前景广阔。我们一直将 ARC-AGI-2 的经验教训融入到设计中,使其尽可能对研究人员有用。
效率是衡量智力的另一个根本概念,我特别兴奋的是,ARC-AGI-3 评分指标将首次对人类与人工智能的行动效率(即学习效率)进行正式比较。
我们很快将分享有关 ARC-AGI-3 的更多信息。与此同时,在这里注册更新,阅读更多关于这里是 ARC-AGI-3, 和在这里玩预览游戏!
2025 年获奖者访谈
最高分
合成数据驱动的集成,由改进的架构师风格的测试时间训练模型和基于 TRM 的组件组成,在竞赛限制下在 ARC-AGI-2 上达到约 24%。
具有递归自我完善和基于视角的评分功能的 2D 感知掩模扩散法学硕士实现了顶级 ARC-AGI-2 性能,比团队的 2024 年自回归系统有了显着提高。
精心设计的测试时间训练管道,结合了 TTFT、增强集成、分词器 dropout 和一些新的预训练技巧,产生具有竞争力的 15.42% ARC-AGI-2 分数。
论文奖
微小递归模型 (TRM) 是一种约 7M 参数的单网络递归模型,具有单独的答案和潜在状态,通过深度监督细化,在 ARC-AGI-1 上达到约 45%,在 ARC-AGI-2 上达到约 8%。
SOAR 是一种自我改进的进化程序综合框架,可以根据自己的搜索轨迹对 LLM 进行微调,将开源 ARC-AGI-1 解决方案性能提升高达 52%,而无需人工设计的 DSL 或解决方案数据集。
CompressARC 是一种基于 MDL 的单谜题训练神经代码高尔夫系统,无需任何预训练或外部数据,在 ARC-AGI-1 上实现约 20%~34%,在 ARC-AGI-2 上实现约 4%。
2025 年总结
如果没有 ARC 奖团队、我们在 Kaggle 的竞赛合作伙伴以及我们的团队的全力支持,ARC 奖是不可能实现的。赞助商。我们不断增强我们的雄心壮志,每个人都奋起迎接挑战。
我想认可我们社区的奉献精神。我们特别感谢马克·巴尼和西蒙·斯特兰德加德感谢他们不断努力构建工具、回答问题并成为社区的资源。
感谢所有前沿人工智能实验室的所有人在 2025 年与我们合作,在 ARC-AGI 上验证他们的新人工智能系统。
我还要向 ARC 奖主席表示衷心的感谢格雷格·卡姆拉特。我非常感谢他去年接受了这个角色。如果没有他每天的动力和坚持让 ARC 变得更好,我们将一事无成。
对创始团队成员的特别认可布莱恩·兰德斯,他继续支持和贡献ARC奖并在今年的关键时刻填补了空白。
最后,感谢我的联合创始人兼 ARC-AGI 创始人 Francois Chollet 发起了 ARC 奖和恩德亚和我一起。
我们受到 ARC-AGI 工作中所有有新想法的人的启发。我们为 ARC 迄今为止在人工智能研究前沿所产生的影响感到自豪。我们坚信最终构建 AGI 的团队今天正在考虑 ARC。我们将继续管理这种关注,尽可能成为 AGI 的最佳北极星。
如果您有兴趣加入 ARC 奖以对 AGI 产生影响,请参阅我们的公开内容角色或联系 team@arcprize.org。