

你好!如果您喜欢这篇文章并希望支持我的独立报告和分析,为什么不订阅我的高级时事通讯呢?每年 70 美元,或每月 7 美元,作为回报,你会收到一份每周时事通讯,通常包含 5000 到 18,000 字,其中包括对英伟达,Anthropic 和 OpenAI 的财务状况, 和人工智能泡沫明显扩大。我刚拿出来一份关于 SaaS 末日的大量仇恨者指南,以及Adobe 仇恨者指南.它有助于支持此类免费新闻通讯!
整个人工智能泡沫建立在一种模糊的必然性之上——如果每个人都相信足够困难,这一切都不会出错,到了某个时候,所有非常明显的问题都会消失。
可悲的是,人们无法战胜物理学。
上周,经济学家保罗·克德罗斯基 (Paul Kedrosky) 提出一个优秀的作品以显示新数据中心容量增加的图表为中心(如添加到管道中,但未上线)在 2025 年第四季度减半(根据数据伍德·麦肯齐):
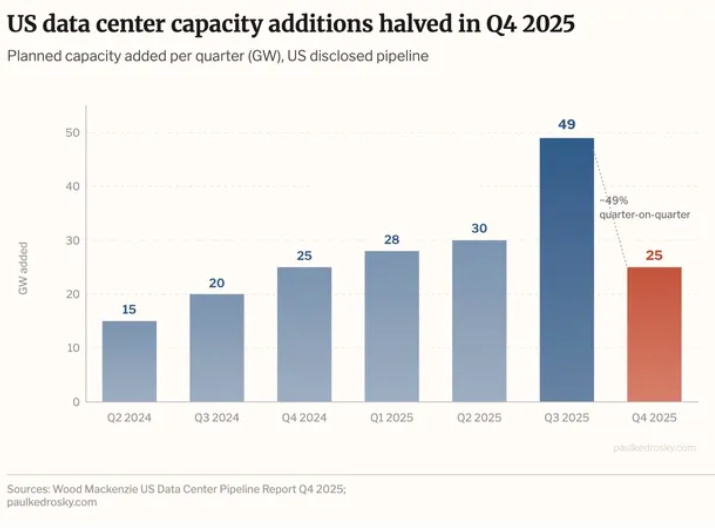
伍德·麦肯齐的报告对其进行了严厉的表述:
美国数据中心容量增加由于负载队列挑战持续存在,从 2025 年第三季度到第四季度减少了一半。这一下降凸显了当前开发环境的困难,并标志着对现有管道项目的关注。同时德克萨斯州 2025 年第四季度扩大管道产能领先优势、新墨西哥州、印第安纳州和怀俄明州的相对增长较大。规划产能继续受到新开发商的重视,其中有少量大型投机性项目,特别针对南部和西南部地区。新墨西哥州的增长归功于新时代能源与数字公司在利县的一个单一、大规模的投机项目。
正如我上面所说,这仅指已存在的容量宣布而不是实际上线的内容,Kedrosky 错过了可以说是最疯狂的图表——已披露的 241GW 数据中心容量,其中只有 33% 实际上正在积极开发中:
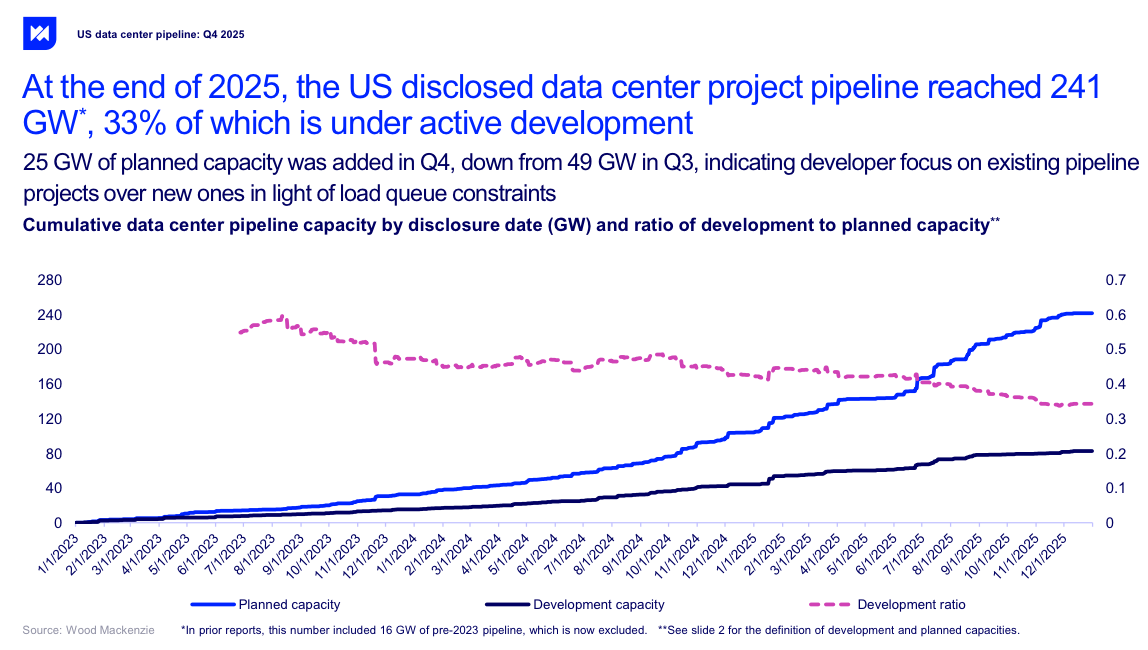
该报告还补充说,大部分承诺电力(58%)用于“仅限电线的公用事业公司”,这意味着公用事业提供商只负责为设施提供电力,而不负责发电。当您构建由耗电的人工智能服务器组成的整个园区时,这是一个大问题。
WoodMac 还补充说,PJM 作为美国最大的公用事业提供商之一,“……仍然陷入困境,公用事业公司的大负荷承诺是 PJM 风险发电队列中认可容量的三倍”,这是一种复杂的说法,“它没有足够的电力。”
这意味着该死的百分之五十八的数据中心需要以某种方式计算出自己的功率。WoodMac 还补充说,周围还有9,480亿美元资本支出全部用于美国数据中心,但资本支出增长自2023年以来首次减速。克德罗斯基补充道:
宣布的总装机容量看起来高达 241 吉瓦,约为美国峰值电力需求的两倍,但其中大部分并不真实。只有三分之一正在建设中,其余的都是充满希望的许可证、投机性土地交易以及采用尚未实际建造的电源的项目。特别是,其中大部分假设是现场天然气工厂,考虑到当前的地缘政治,这是一个令人担忧的假设。最严重的问题是在大西洋中部。区域电网运营商 PJM 向数据中心做出的电力承诺大约是新一代实际上网速度的三倍。有人会等待很长时间,或者支付比他们预期更多的费用,或者两者兼而有之。
让我们简化一下:
- 在已公布的美国数据中心中,实际上只有 33% 正在建设中,其余的都处于模糊的“规划”水平。这相当于约 79.53 吉瓦的电力,或 61 吉瓦的 IT 负载。
- “积极开发”还指任何(我引用的)“正在开发或建设中”的事物,意思是“我们已经获得了土地,并且仍在研究如何处理它”。
- 当你做数学计算时,这是非常明显的。61GW 的 IT 负载将是数十万个 NVIDIA GB200 NVL72 机架 - 价值超过一万亿美元的 GPU,每个 72 个 GPU 机架 300 万美元 - 并且基于以下事实去年数据中心债务交易额仅为 1,785 亿美元,我不认为其中很多现在实际上正在建造。
- 即使有,也没有足够的电量来启动它们。
- NVIDIA 声称将在 2025 年至 2027 年间销售 1 万亿美元的 GPU, 和正如我之前计算的,其销量约为 1.6GW(以 IT 负载而言,即多少电力只是GPU 每个季度都会消耗 GPU 的电量,如果算上所有相关设备以及实际获取电力的挑战,则仅需要 1.95GW 的电力才能运行。
- 这些数据都没有涉及数据中心真正上线了。
您要查找的术语是数据中心吸收,这是(引用数据中心动态)“...占用的、创收的 IT 负载的净增长,”美国主要市场的新增产能从2024年的1.8GW增长到2025年的2.5GW 根据世邦魏理仕. . . . . . . . . . . . . . . . . .
定义旁注!– 托管 – 空间是指建造后出租给其他人的数据中心空间,而不是专门为公司建造的数据中心(例如 Microsoft 的 Fairwater 数据中心)。有趣的是,一些人(例如 Avison Young)似乎将 Crusoe 的开发(例如 Stargate Abilene)视为并置构建,这使得我很快就会得到的并置数字更能体现更大的图景。
问题是,这个数字实际上并不能表达新启用的数据中心。有人扩建项目以再承接 50MW 仍然算作“新吸收”。
当您添加其他报告时,事情会变得更加混乱。Avison Young 关于数据中心吸收的报告发现,2017 年新增容量为 700MW2025 年第一季度,第二季度1.173GW,第三季度略高于 1.5GW,第四季度略高于 2.033GW(我在任何地方都找不到其第三季度报告),总计 5.44GW,完全处于“托管”状态,这意味着建造的建筑物可以出租给其他人。
然而这种方法还存在另一个问题:这些是已“交付”的设施或有一个“忠诚的租户。”“已交付”可能意味着“设施已移交给客户,但它实际上是一个等待安装的动力外壳(仓库)”,或者可能意味着“客户已启动并运行。”“承诺租户”可能意味着“我们已经签署了合同,并且我们正在筹集资金”(例如Nebius 从 Meta 合约中筹集资金,用于在未来某个时候建设数据中心)。
我们可以通过使用 DataCenterHawk 中的定义(Avison Young 从中获取数据)来更接近,其吸收定义如下:
为了衡量需求,我们想知道客户在特定时间段内租用了多少容量。在 datacenterHawk,我们每季度计算一次。得到的数字就是所谓的吸收率。假设 DC#1 已投入运行 10 MW。目前已租赁 9 兆瓦,还有 1 兆瓦可供使用。在一个季度的时间里,DC#1 将最后 MW 出租给了一些租户。他们本季度的吸收量将为 1 兆瓦。它可能会变得有点复杂,但这就是基本概念。
太棒了!除了艾维森·杨选择以完全不同的方式定义吸收– 数据中心(无论处于何种建设状态)已被租用或“交付”,这意味着“一个完全准备就绪的数据中心”或“一个带电的空仓库”。
另一方面,世邦魏理仕将吸收定义为“占用的净增长”,创收的IT 负载,包括超大规模数据中心。其报告还包括夏洛特、西雅图和明尼阿波利斯等较小的市场,另外增加了 216MW 的实际吸纳容量新的、现有的创收能力。
所以这大约是 2.716GW实际上,新的数据中心已上线。它不包括像南弗吉尼亚州或俄亥俄州哥伦布这样的地区——艾维森·杨报告中的两个巨大热点地区——而且我找不到一点实际证据具有重要意义的创收、开启、真实的数据中心容量大规模增加。DataCenterMap 显示哥伦布有 134 个数据中心,但截至 2025 年 8 月,哥伦布地区约有 506MW总共据《哥伦布快报》报道,尽管库什曼和韦克菲尔德2026年2月声称拥有1.8GW。事情趋于平衡
更多当你读到它时感到困惑高纬环球 (Cushman and Wakefield) 估计新增主机托管供应量约为 4GW于 2025 年“交付”,但该术语在其实际报告中并未给出定义,并且出于某种原因缺乏吸收数据。2025 年上半年报告然而,其中包括总计约 1.95GW 容量的吸纳量……没有定义吸纳量,让我们面临与 Avison Young 完全相同的问题。 尽管如此,根据这些数据点,我可以放心地估计
2025 年,北美数据中心的吸纳量(当数据中心的 IT 负载实际开启和运行时)约为 3GW,总功率约为 3.9GW。这个数字是
他妈的灾难。今年早些时候,TD Cowen 的 Jerome Darling
告诉我 GPU 及其相关硬件的成本约为每兆瓦 3000 万美元。3GW 的 IT 负载(如 GPU 及其相关设备的功耗)相当于约 900 亿美元的 NVIDIA GPU 和相关硬件,这些负载将包含在 NVIDIA 的“数据中心”收入部分中:
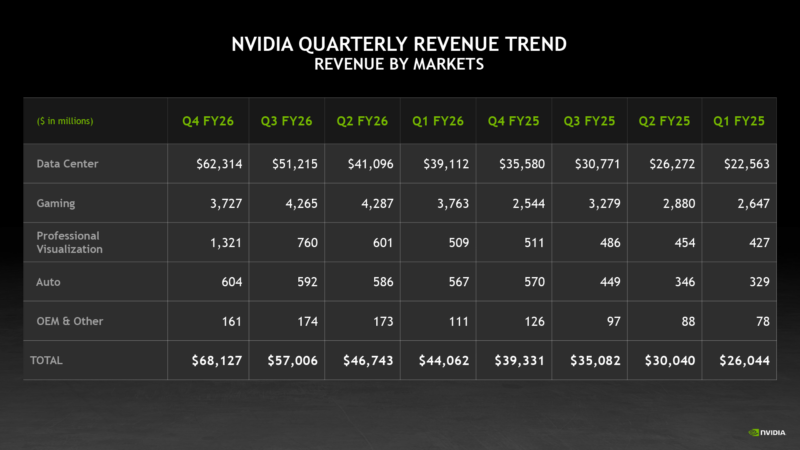
美国市场约占 NVIDIA 收入的 69.2%2026 财年约为 1,496 亿美元(令人烦恼的是,该活动从 2025 年 2 月持续到 2026 年 1 月)。NVIDIA 数据中心部门的总体收入为 1,957 亿美元,这使得美国数据中心的采购额约为 1,350 亿美元,而未安装的 GPU 和相关技术价值约为 440 亿美元。
随着 NVIDIA GPU 销售的加速,现在安装和运行需要大约 6 个月的时间单季度的销售额。因为这些是 Blackwell(我想是一些新的下一代 Vera Rubin)GPU,由于其更大的功率和冷却要求,它们很可能会进入新版本,虽然有些可以理论上将对旧建筑进行改造以适应它们,NVIDIA 日益集中化(如专注于少数非常大的客户)收入很大程度上表明存在大型经销商,例如戴尔或超微(我稍后会谈到)或台湾 ODM比如富士康和广达 他们为超大规模扩建制造大量服务器。
我还应该补充一点,超大规模企业购买 GPU 供其托管合作伙伴安装是很常见的,这就是为什么 Nebius 和 Nscale 以及其他合作伙伴筹集的资金从未超过数十亿美元来支付建设成本。
越来越明显的是,数据中心的建设速度明显慢于 NVIDIA 的 GPU 销售速度,而 NVIDIA 的 GPU 销售量每个季度都在大幅增长。
即使你认为人工智能是最大、最巨大、最特别的男孩:提前两到四年购买这些东西有什么意义呢?Jensen Huang 每年都会发布一款新 GPU!
当他们真正得到维拉鲁宾的所有布莱克威尔时,已经两岁了!当我们安装这些 Vera Rubins 时,其他一些新的 GPU 将击败它!
在我们进一步讨论之前,我想明确回答“数据中心需要多长时间才能建成?”这个问题有多么困难。你不能真正说“每兆瓦[时间]”,因为每达到 100 兆瓦左右,事情就会变得更加复杂。正如我将要介绍的,星际之门阿比林花了两年时间才达到 200MW电源。
不是 IT 负载。电源. . .
不管怎样,“有多少数据中心容量上线?”这个问题也很烦人。
视线– 的研究 – 估计“去年有近 6GW 的[全球数据中心电力] 容量上线 – – 发现虽然 140 个项目预计 2026 年将有 16GW 的容量上线,但目前只有 5GW 正在建设中,而且不知何故并没有说明这一点 – 也许每个人都在撒谎时间表。 –
Sightline 认为,到 2026 年设想的数据中心管道中的一半可能永远不会实现,其中 11GW 容量处于“已宣布”阶段,并且“...尽管典型的建设时间表为 12-18 个月,但没有明显的施工进展。”“正在建设中”也可以表示以下任何内容:“单根钢梁— 到 — 即将完成。 —
这些数字也是基于 5GW容量,意味着约 3.84GW 的 IT 负载,或约 1115 亿美元的 GPU 及相关设备,约占 NVIDIA 2026 财年收入的 57.5%那实际上正在建造中。
Sightline(以及基本上其他所有人)认为,存在阻碍数据中心发展的功率瓶颈,并且加缪解释最大的问题是缺乏传输能力(可以移动的电量)和发电(产生电力本身):
延迟的最大驱动因素很简单:我们的电力系统没有足够的额外传输容量和发电量来 100% 地满足数十吉瓦的新高利用率需求。数据中心需要的全天候电力水平可以与小城市的需求相媲美或超过,而建设新的传输基础设施和发电需要多年的许可、土地征用、供应链管理和建设。
加缪补充说,美国也并没有真正准备好立即增加这么多力量:
在公用事业内部,规划人员和工程师正在努力连接新负载。但规划者可用的工具是为了将电力线延伸到新社区或随着社区的发展而升级设备的。它们的设计目的并不是要在新一代应用不断堆积的情况下分析 50 个新的服务请求,每个请求的容量为 100 MW。结果,规划人员和工程师不知所措;他们一边努力审查新应用程序,一边配置新工具,以更好地应对这一规模的挑战。与大多数 ISO 和公用事业公司都有明确定义的步骤的发电互连不同,评估大负荷的过程通常更加临时化。这也使得采用正确的工具变得更加困难。事实上,大多数公用事业公司和 ISO/RTO 仍在制定正式的研究程序。
尽管如此,我还认为还有另一个更明显的原因:建设数据中心所需的时间比任何人想象的都要长,事实证明,我们在 2025 年仅在美国增加了 3GW 左右的实际容量。NVIDIA 在未来几年内销售 GPU,其增长能力,甚至维持当前收入的能力,完全取决于它是否有能力让人们相信这是合理的。
让我举个例子。OpenAI 和 Oracle 的 Stargate 阿比林数据中心项目于 2024 年 7 月首次宣布为 200MW 数据中心。2024年10月,Crusoe、Blue Owl和Primary Digital Infrastructure成立合资公司筹集了 34 亿美元,预计将于 2025 年交付 200MW 产能。”土地开发商 Lancium 的 2025 年中期演示表示到 2025 年将拥有“1.2GW 在线装机容量”。2025 年 5 月公告、Crusoe、Blue Owl 和 Primary Digital Infrastructure 宣布创建价值 150 亿美元的联合车辆,并表示阿比林现在将由 8 栋建筑组成,前两栋建筑将在“2025 年上半年”之前通电,其余建筑将“在 2026 年中期之前通电”。每栋建筑将配备 50,000 个 GPU,总 IT负载预计为 880MW 左右,总功耗为 1.2GW。
我对讨论 OpenAI 不采取行动不感兴趣据称计划对阿比林进行扩建,因为它从未存在过,也永远不会发生. . .
2025 年 12 月,Oracle 表示已“交付”96,000 个 GPU,二月份,甲骨文仍然只指两座建筑物,可能是因为这就是全部完成的事情。我在阿比林的消息来源告诉我,三号楼即将完工,但是……这个东西预计会在 2026 年中期启用。开发商 Mortensen 声称整个项目将于 2026 年 10 月完工,显然,公然不会这样做。
我讨厌用阴谋论的方式说话,但这感觉像是在媒体积极参与下的公然掩盖。CNBC 于 2025 年 9 月报道称 –价值 5000 亿美元的 Stargate 项目的第一个数据中心在德克萨斯州开放,指的是一个数据中心,其八分之一的 IT 负载处于“在线”和“正常运行”状态,并且克鲁索两周后加入它“已经上线”、“已启动并运行”以及“继续快速进展”,所有这些都会让读者和观众认为“哇,星际之门阿比林已经启动并运行”,尽管它比计划晚了几个月甚至几年。
按照目前的建设速度,阿比林星际之门将于 2027 年末的某个时候全面建成。Oracle 的华盛顿港数据中心,截至 2026 年 3 月 6 日,由一根钢梁组成。德克萨斯州沙克尔福德星际之门于 2025 年 12 月 15 日破土动工, 和截至 2025 年 12 月,新墨西哥州 Stargate 的建设似乎才刚刚开始。Meta 位于印第安纳州的 1GW 数据中心园区于 2026 年 2 月才开始建设. . .
而且,尽管微软试图误导大家其威斯康星州数据中心已经“抵达”并“已建成”,即使再深入一英寸,也表明实际上几乎没有什么东西上线了——并且考虑到第一个数据中心耗资 33 亿美元(请记住:每兆瓦 1400 万美元仅用于施工),我想微软已经成功为 Fairwater 提供了约 235MW 的电力。
微软希望你认为它带来了千兆瓦的在线电力(总是以将来时态提及),因为微软和其他人一样,正在以极其缓慢的速度建设数据中心,因为建设需要永远的时间,即使你有能力,而没有人能做到!
百兆瓦数据中心的概念才出现了几年,而且我实际上找不到任何类型的已建成的、正在使用的千兆瓦数据中心,只是为 OpenAI 建造理论上的 Stargate 园区的模糊承诺,OpenAI 是一家无力支付账单的公司。
每个人都在抱怨“如果数据中心没有电怎么办”,而他们应该考虑数据中心是否真的正在建设中。微软2025 年 9 月自豪地夸耀关于其与 Nscale 在英国劳顿建造“英国最大的超级计算机”的意图,截至 2026 年 3 月,它确实是充满塔架和废金属的脚手架场。《星际之门》阿比林已被困在两座建筑中超过六个月。
实际发生的情况是这样的:数据中心交易的资金是由热心的私人信贷怪物提供的,他们根本不知道他妈的是什么。这些交易通常是由过于热心的记者宣布的,他们懒得检查以前的数据中心是否建成,作为大规模的“数千兆瓦交易”,然后没有人跟进来检查是否真的发生了任何事情。
任何人为这些项目之一提供资金所需要的只是一位足够热心的金融家以及与 NVIDIA 的联系。Nebius 所要做的就是筹集37.5亿美元债务是为了与Meta签署协议对于不存在的数据中心容量,可能需要三到四年才能建立(这永远不会发生)。Nebius 尚未完成微软新泽西州瓦恩兰数据中心,本来应该是 –100MW时– 到 2025 年底,但是截至 2026 年 2 月似乎只有 50MW(第一阶段)可用. . .
我只想说:我认为很多数据中心交易都是垃圾,永远不会建成,因此永远不会得到报酬。科技行业利用媒体对建设或电力时间表缺乏了解这一点,这是可以理解的,以此来炮制无数有关“数据中心容量正在建设中”的故事,以此来掩盖日益严重的丑闻:数千亿个 NVIDIA GPU 被出售用于可能永远不会建成的项目。
这些东西还没有建成,或者即使它们建成了,它也正在消失,方式比预期的时间长,这意味着该债务的利息正在累积。花费的时间越长,购买更多 NVIDIA GPU 就越不合理——毕竟,如果数据中心的建设时间从 18 个月到三年不等,那么您为什么还要购买更多呢?你要把它们放在哪里,Jensen?
这也严重质疑了私人信贷和其他金融机构为这些项目提供资金的兴趣,因为大部分经济潜力来自于这些项目建成并拥有稳定租户的想法。此外,如果人工智能计算的供应是一个瓶颈,这表明当(或如果)该瓶颈被清除时,将会突然出现巨大的供应过剩,从而降低正在建设的数据中心的整体价值——顺便说一下,这些数据中心都装满了 Blackwell GPU,到数据中心最终启用时,这些 GPU 已经有两三年的历史了。
那是在你到达之前事实上,人工智能数据中心背后的巨额债务使它们都非常无利可图,或者那个他们的客户是每年损失数亿或数十亿美元的人工智能初创公司,或者说 NVIDIA 是股市上最大的公司,并表示估值是数据中心建设热潮的结果,而数据中心建设热潮似乎正在减速,即使与 NVIDIA 的销售额相比,它的运营速度并不缓慢。
不发声不专业或者什么也没有,但是到底是怎么回事?我们在美国拥有 241GW 的“计划”产能,其中只有 79.5GW 处于“积极开发”状态,但当你深入挖掘时,实际上在建产能只有5GW?�
整个人工智能泡沫是一个该死的海市蜃楼。你听到的每一个“数千兆瓦”数据中心都是一个白日梦,只不过是几份合同和一些家伙双手叉腰说“兄弟,我们他妈的会变得非常富有!”,因为他们从私人信贷中吸走资金,进而从你身上吸走资金,因为私人信贷从哪里获得资本?没错。很多来自养老基金和保险公司。
现实是这样的:数据中心需要很长时间。每个谈论“合同计算”或“计划容量”的超大规模提供商和新云也可能是在告诉您他们计划与格林奇和戈多共进晚餐。人工智能的疯狂建设将被视为有史以来最大的资本浪费之一(套用JustDario的话),而且我预计您正在阅读的大多数数据中心交易根本不会建成。
事实上,有大量关于数据中心建设的数据等等很少关于的数据已完成建筑表明,那些准备报告的人参与了骗局。我赞扬 CBRE、Sightline 和 Wood Mackenzie 有勇气甚至轻轻地反驳这种说法,即使他们通过混淆“能力”或“权力”等术语来做到这一点,而记者和其他分析师肯定会误解。
在某些情况下,已经花费了数千亿美元购买 GPU年提前投入正在建设的数据中心,这意味着 NVIDIA 2025 年和 2026 年的收入将需要到 2028 年至 2029 年才能真正投入运营,这是一个重大假设:其中任何一个实际上都已建成。
我认为这样问也很公平钱实际去向了哪里。2025 年美国数据中心交易价值 1,785 亿美元的交易似乎不会给任何相关方带来任何直接(甚至未来)利益。
我还想知道是否确实存在使这一切有价值的需求,或者人们实际上为这种计算支付了多少钱。
如果我们假设美国上线了 3GW 的 IT 负载容量,那么(理论上)这应该意味着数百亿美元的收入,这要归功于“对人工智能的永不满足的需求”,但似乎没有人从这些数据中心获得大量收入。
Applied Digital 2025 财年营收仅为 1.44 亿美元(为此损失了 2.31 亿美元)。CoreWeave,声称拥有 –有功功率850MW(或约 653MW 的 IT 负载)——到 2025 年底(高于 2025 年的 420MW)2025 财年第一季度,或 323MW 的 IT 负载),收入 51.3 亿美元(亏损 12 亿美元)税前)2025 财年. . .
尼比乌斯?2.28 亿美元,亏损 1.229 亿美元170MW 的有功功率(或约 130MW 的 IT 负载)。Iren 上季度亏损 1.554 亿美元,上季度亏损 1.847 亿美元,这还包括释放 1.825 亿美元的递延税负债。Equinix 上一财年的收入约为 92 亿美元, 和虽然它盈利了,目前尚不清楚其中有多少来自其庞大且已存在的数据中心组合,尽管考虑到 Equinix 吹嘘其“多兆瓦”数据中心计划,这一数字可能很大没有讨论其实际容量。
当然,谷歌、亚马逊和微软拒绝透露他们的人工智能收入。根据我去年的报告,截至 2025 年 9 月,OpenAI 在 Azure 上花费了约 86.7 亿美元,并且亚马逊网络服务同期的人类收入约为 26.6 亿美元。作为人工智能计算的两个最大消费者,这在很大程度上表明对人工智能服务的实际需求相当疲弱,并且大部分由少数公司(或运行自己的服务的超大规模企业)占据。
到了某个时候,现实就会显现出来,NVIDIA GPU 上的支出将会有拒绝。这么多年在未来投入了多少资金,这确实很疯狂,而且值得注意的是,没有其他人对此感到担忧。
像“GPU 要去哪里?”和“实际安装了多少 GPU?”这样的简单问题都没有得到解答,因为一篇又一篇文章都在讨论价值数十亿美元的大规模数据中心计算交易,而按照这个速度,2030 年之前是不会建成的。
我认为这是方便仅仅将其归咎于电力问题,而现实显然是基于从一开始就没有任何意义的施工时间表。如果是的话只是如果出现电力问题,更多的数据中心将接近或位于终点线,等待电源开启。相反,像《星际之门》阿比林这样的著名项目的建设速度非常缓慢,因为热切的记者声称四分之一的建筑已经投入使用距离它们原定开启已近一年是某种成就。
还有一个非常非常明显的丑闻:股票市场上最大的公司 NVIDIA 正在通过未安装的芯片赚取数千亿美元的收入。这真他妈的奇怪,我根本不明白它是如何每个季度不断超出并提高预期的,因为大多数客户可能会在下一个季度使用他们当前购买的产品十年。
假设 Vera Rubin 实际在 2026 年发货,我们有理由相信人们会在 2028 年(甚至更远)之前安装这些东西,而且前提是到那时一切都不会崩溃。你为什么要费心呢?这有什么意义,尤其是当您坐在一堆 Blackwell GPU 上时?
我们为什么要做任何这个?
上周还推出了真正的疯狂的关于 Supermicro 的故事,Supermicro 是 CoreWeave 和 Crusoe 使用的 GPU 经销商,联合创始人 Wally Liaw 和其他几名同谋因向中国出售价值数亿美元的 NVIDIA GPU 而被捕,意图再销售数十亿美元。
Liaw 是 Supermicro 的联合创始人之一,此前因2018年会计丑闻而辞职Supermicro 无法提交其年度报告,只能(根据兴登堡研究中心的出色报告) 重新雇用2021年担任顾问,并于 2023 年恢复董事会成员,每提交8K. . .
就在他被捕前几天,Liaw 在 NVIDIA GTC 会议上炫耀,将未命名的液体倒入冰雪橇中,并让两个人远离 NVIDIA 首席执行官黄仁勋 (Jensen Huang)。廖LinkedIn 上还出现了祝贺 Lambda 首席执行官任命新首席财务官的视频,以及握手(与尚未被捕或被起诉的超微首席执行官梁朝伟)与 Crusoe(建设 OpenAI 阿比林数据中心的公司)首席执行官 Chase Lochmiller 合影. . .
起诉书中没有提及 Supermicro 的名字,我认为原因是完全正确的正常和与维持人工智能派对无关。尽管如此,Liaw 及其同谋被指控通过交易对手和经纪人网络向中国运送了价值数亿美元的 NVIDIA GPU,其中在 2025 年 4 月至 5 月中旬期间运送了超过 5.1 亿美元。虽然起诉书没有具体说明具体细节,但它证实了一些Blackwell GPU 进入了中国,我敢打赌一定会有不少。
主流媒体已经不再思考这个故事,尽管 Supermicro 是 NVIDIA 设备的大型经销商,贡献了数十亿美元的收入,其中至少 5 亿美元显然将用于中国。事实上,该案中没有具体提到超微公司的名字,这一事实足以让他们从脑海中抹去整个故事,以及任何关于超微公司的疑问。NVIDIA(特别是黄仁勋)怎么不知道。
这也不是关闭这是唯一一次发生这种情况。去年年底,彭博社报道on Singapore-based Megaspeed — a (to quote Bloomberg) “once-obscure spinoff of a Chinese gaming enterprise [that] evolved into the single largest Southeast Asian buyer of NVIDIA chips†— and highlighted odd signs that suggest it might be operating as a front for China.Â
As a neocloud, Megaspeed rents out AI compute capacity like CoreWeave, and while NVIDIA (and Megaspeed) both deny any of their GPUs are going to China, Megaspeed, to quote Bloomberg, has “something of a Chinese corporate twinâ€:
This firm used similar presentation materials to Megaspeed’s, had a nearly identical website to a Megaspeed sub-brand and claimed Megaspeed’s Southeast Asia employees as its own.It’s also posted job ads at and near the Shanghai data center whose rendering was used in Megaspeed’s investor deck — including for engineering work on restricted Nvidia GPUs.
Bloomberg reported that Megaspeed imported goods “worth more than a thousand times its cash balance in 2023,†with two-thirds of its imports being NVIDIA products.
The investigation got weirder when Bloomberg tried to track down specific circuit boards that NVIDIA had told the US government were in specific sites: Data centers aren’t the only Megaspeed facilities Nvidia visited.The vast majority of Megaspeed’s $2.4 billion worth of Bianca boards, the circuit boards that house Nvidia’s top-end GB200 and GB300 semiconductors, were unaccounted for at the sites Nvidia described to Washington.After Bloomberg asked about those products, the chipmaker went to separate Megaspeed warehouses, an Nvidia official said, and confirmed the Bianca boards are there.This person declined to specify the number observed in storage, nor where and when the chips — imported more than half a year ago — would be put to use.“Building data centers is a complex process that takes many months and involves many suppliers, contractors and approvals,†an Nvidia spokesperson said.
Things get weirder throughout the article, with a Chinese company called “Shanghai Shuoyao†having a near-identical website and investor deck (as mentioned) to Megaspeed, with several of the “computing clusters under construction†actually being in China.Â

Things get a很多weirder as Bloomberg digs in, including a woman called “Huang†that may or may not be both the CEO of Megaspeed和an associated company called “Shanghai Hexi,†which is还有owned by the Yangtze River Delta project… who was also photographed sitting next to Jensen Huang at an event in Taipei in 2024.
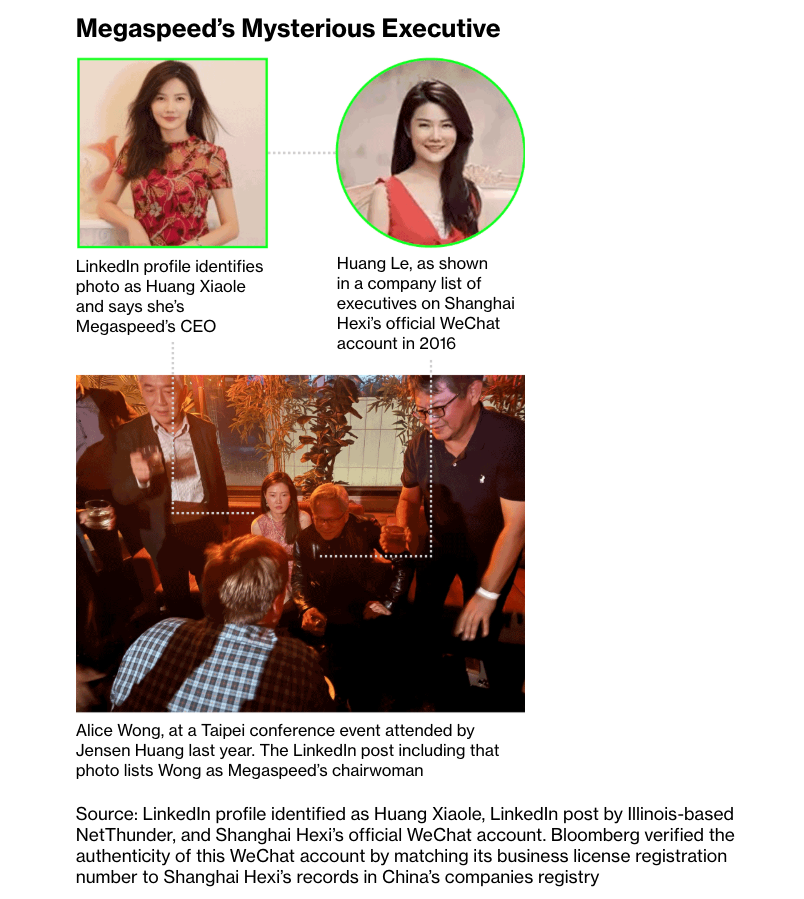
While all of this isextremely weird和可疑,I must be clear there is no陈述性的answer as to what’s going on, other than that NVIDIA GPUs are absolutely making it to China, somehow.
I also think that it would be really tough for Jensen Huang to not know about it, or for billions of dollars of GPUs to be somewhere without NVIDIA’s knowledge. Anyway, Supermicro CEO Charles Liang has yet to comment on Wally Liaw or his alleged co-conspirators, other than a statement from the company that says that their acts were “ a contravention of the Company’s policies and compliance controls .â€Â Jensen Huang does not appear to have been asked if he knew anything about this — not Megaspeed, not Supermicro, or really any challenging question of any kind for the last few years of his life. Huang did, however, say back in May 2025 that there was “no evidence of any AI chip diversion,’ and that the countries in question “monitor themselves very carefully.â€Â For legal reasons I am going to speak very carefully: I cannot say that Jensen is wrong, or lying, but I think it’s incredible, remarkable even, that he had no idea that any of this was going on.真的吗?Hundreds of millions if not
数十亿
of dollars of GPUs are making it to China —as reported by The Information in December 2025— and Jensen Huang
had no idea?I find that highly unlikely, though I obviously can’t say for sure.In the event that NVIDIA had knowledge — which I am not saying it did, of course — this is a huge scandal that, for the most part, nobody has bothered to keep an eye on outside of a few brave souls at The Information and Bloomberg who give a shit about the truth.Has anybody bothered to ask Jensen about this?People talk to him on camera all the time. Sidenote : Earlier today, US Senators Jim Banks and Elizabeth Warren issued a letter to Howard Lutnick, Trump' s Commerce Secretary , demanding the Department of Commerce take “all necessary and appropriate actions†to stop the flow of NVIDIA chips to China, including potentially block exports to countries believed to be intermediaries, like Malaysia, Thailand, Vietnam, and Singapore.The arrest of Liaw has, it seems, ruffled some feathers in Washington, and I would not be shocked to see Huang sat before a congressional inquiry at some point.I’ll also add that I am shocked that so many people are just shrugging and moving on from Supermicro, which is a major supplier of two of the major neoclouds (Crusoe and CoreWeave) and one of the minors (Lambda, which they also rents cloud capacity to).The idea that a company had no idea that several percentage points of its revenue were flowing directly to China via one of its co-founders is an utter joke.I hope we eventually find out the truth.
Nevertheless, this kind of underhanded bullshit is a sign of desperation on the part of just about everybody involved.
The End of Software Engineering — Hyperscalers Are Forcing AI On Their Workers, Destroying The Quality Of Their Products, and Crashing Their ServicesSo, I want to explain something very clearly for you, because it’s important you understand how fucked up shit has become:hyperscalers are forcing everybody in their companies to use AI tools as much as possible, tying compensation and performance use to token burn, and actively encouraging non-technical people to vibe-code features that actually reach production. In practice, this means that大家
is being expected to dick around with AI tools all day, with the expectation that you burn massive amounts of tokens and, in the case of designers working in some companies, actively code features without ever knowing a line of code. “How do I know the last part?Because a trusted source told me — and I’ll leave it at that†One might be forgiven for thinking this means that AI has taken a leap in efficacy, but the actual outcomes are a labyrinth of half-functional internal dashboards that measure random user data or convert files, spending hours to save minutes of time at some theoretical point.
While non-technical workers aren’t necessarily allowed to ship directly to production, their horrifying pseudo-software, coded without any real understanding of anything, is expected to be “fixed†by actual software engineers who are also expected to do their jobs.
These tools also allow near-incompetent Business Idiot software engineers to do far more damage than they might have in the past.
LLM use is relatively-unrestrained (and actively incentivized) in at least one hyperscaler, with just about anybody allowed to spin up their own OpenClaw “AI agent†(read: series of LLMs that allegedly can do stuff with your inbox or Slack for no clear benefit,other than their ability to delete all of your emails
)。In Meta’s case , this ended up causing a severe security breach: According to internal Meta communications and an incident report seen by The Information, a major security alert occurred last week after a Meta software engineer used an in-house agent tool, similar to OpenClaw, to analyze a technical question that another Meta employee had posted on an internal discussion forum.根据内部通讯,在完成分析后,人工智能代理在论坛中发布了对原始问题的回复,就技术问题提供了建议。
该代理人未经员工同意就这样做了。
According to The Information, Meta systems storing large amounts of company and user-related data were accessible to engineers who didn’t have permission to see them, and was marked a sec-1 incident, the second highest level of severity on an internal scale that Meta uses to rank security incidents. The incident follows multiple problems caused at Amazon by its Kiro and Q LLMs.I quote Business Insider ’s Eugene Kim: On March 2, customers across Amazon marketplaces saw incorrect delivery times when adding items to their carts.
The incident led to nearly 120,000 lost orders and roughly 1.6 million website errors.Amazon's AI tool Q was one of the primary contributors that triggered the event, according to an internal review.On March 5, another outage caused a 99% drop in orders across Amazon's North American marketplaces, resulting in 6.3 million lost orders, one of the internal documents stated.One key factor was a production change that was deployed without using a formal documentation and approval process called Modeled Change Management.Despite the furious (and exhausting) marketing campaign around “the power of AI code,†I believe that these events are just the beginning of the真实consequences of AI coding tools: the slow destruction of the tech industry’s software stack.Â
LLMs allow even the most incompetent dullard to do an impression of a software engineer, by which I mean you can tell it “make me software that does this†or “look at this code and fix it†and said LLM will spend the entire time saying “you got this†and “that’s a great solution.â€Â
The problem is that while LLMs can write “all†code, that doesn’t mean the code is good, or that somebody can read the code and understand its intention (as these models do not think), or that having a lot of code is a good thing both in the present and in the future of any company built using generative code.Â
LLM-based code is often verbose, and rarely aligns with in-house coding guidelines and standards, guaranteeing that it’ll take far longer to chew through, which naturally means that those burdened with reviewing it will either skim-read itor feed it into another LLM to work out what the hell to do.Worse still, LLM use is also entirely directionless.
为什么是任何人
at Meta using an OpenClaw?What is the actual thing that OpenClaw does, other than burn an absolute fuck-ton of tokens? Think about this very, very simply for a second: you have given every engineer in the company the explicit remit to write all their code using LLMs, and incentivized them to do so by making sure their LLM use is tracked.You have now massively increased both the operating costs of the company (through token burn costs)
和
the volume of code being created.Â
To be explicit, allowing an LLM to write all of your code means that you are no longer developing code, nor are you learning how to develop code, nor are you going to become a better software engineer as a result.This means that, across almost every major tech company,
software engineers are being incentivized to stop learning how to write softwareor solve software architecture issues。� If you are just a person looking at code, you are only as good as the code the model makes, and asMo Bitar
recently discussed, these models are built to galvanize you, glaze you, and tell you that you’re remarkable as you barely glance at globs of overwritten code that, even if it functions, eventually grows to a whole built with no intention or purpose other than what the model generated from your prompt. Things only get worse when you add in the fact that hyperscalers like元
和亚马逊love to lay off thousands of people at a time,which makes it even harder to work out why something was built in the way it was built, which iseven harder when an LLM that lacks any thoughts or intentions builds it.
Entire chunks of multi-trillion dollar market cap companies are being written with these things, prompted by engineers (and non-engineers!) who may or may not be at the company in a month or a year to explain what prompts they used. We’re already seeing the consequences!Amazon lost hundreds of thousands of orders!Meta had a major security breach!
The foundations of these companies are being rotted away through millions of lines of slop-code that, at best, occasionally gets the nod from somebody who has “software engineer†on their resume, andthese people keep being fired too, raising the likelihood that somebody who knows what’s going on or why something is built a certain way will be able to stop something bad from happening. Remember: Google, Amazon, Microsoft, and Meta全部hold vast troves of personal information, intimate conversations, serious legal documents, financial information, in some cases even social security numbers, andall four of them along with a worrying chunk of the tech industry are actively encouraging their software engineers to stop giving a fuck about software.� Oh, you’re
so much fasterwith AI code?这实际上意味着什么?What have you built?Do you understand how it works?
你有吗look at the codebefore it shipped, or did you assume that it was fine because it didn’t break? This is creating a kind of biblical plague within software engineering — an entire tech industry built on reams of unmanageable and unintentional code pushed by executives and managers that don’t do any real work.LLMs allow the incompetent to feign competence and the unproductive to produce work-adjacent materials borne of a loathing for labor and craftsmanship, and lean into the worst habits of the dullards that rule Silicon Valley.
All the Valley knows is成长, and “more†is regularly conflated with “valuable.†The New York Times’ Kevin Roose — in a shocking attempt at journalism —recently wrote a piece celebrating the competition within Silicon Valley to burn more and more tokens using AI models:
An engineer at OpenAI processed 210 billion “tokens†— enough text to fill Wikipedia 33 times — through the company’s artificial intelligence models over the last week, the most of any employee.
At Anthropic, a single user of the company’s A.I.coding system, Claude Code, racked up a bill of more than $150,000 in a month.And at tech companies like Meta and Shopify, managers have started to factor A.I.use into performance reviews, rewarding workers who make heavy use of A.I.tools and chastening those who don’t.
This is the new reality for coders, some of the first white-collar workers to feel the effects of A.I.
as it sweeps through the economy.人工智能。was supposed to help tech companies boost productivity and cut costs.But it has also created an expensive new status game, known as “tokenmaxxing,†among A.I.-obsessed workers who are desperate to prove how productive they are.
Roose explains that both Meta and OpenAI have internal leaderboards that show how many tokens you’ve used, with one software engineer in Stockholm spending “more than his salary in tokens,†though Roose adds that his company pays for them.
Roose describes a truly sick culture, one whereOpenAI gives awards to those who spend a lot of money on their tokens, adding that he spoke with several tech workers who were spendingthousands of dollars a dayon tokens “for what amount to bragging rights.†Roose also added one more疯狂的detail: that one person found a loophole in Claude’s $20-a-month using a piece of software made by Figma that allowed them to burn$70,000 in tokens。
Despite all of this burn, Roose struggled to find anybody who was able to explain what they were doing beyond “maintaining large, complex pieces of software using coding agents running in parallel,†but managed to actually find one particularly useful bit of information — that all of this might be performative: They said, by and large, that A.I.
coding tools were making them more productive.But some also framed their use of A.I.as a strategic move — a way to signal, to their colleagues and bosses, that they’re keeping up with the times, as the era of human coding appears to be coming to an end.
I do give Roose one point for wondering if “...any of these tokenmaxxers [were] producing anything good, or whether they [were] merely spinning their wheels churning out useless code in an attempt to look busy.†Good job Kevin. That being said, I find this story horrifying, and veering dangerously close to the actions of drug addicts and cult followers.
Throughout this story in one of the world’s largest newspapers, Roose fails to find a single “tokenmaxxer†making something that they can actually describe, which has largely been my experience of evaluating任何人who talks nonstop about the power of “agentic coding.â€Â
These people are sick, and are participating in a vile, poisonous culture based on needless expenses and endless consumption.Â
Companies incentivizing the金额 of tokens you burnare actively creating a culture that trades excess for productivity, and incentivizing destructive tendencies built around constantly having tofind stuff to do而不是do things with intention. They are guaranteeing that their software will be poorly-written and maintained, all in the pursuit of “doing more AI†for no reason other than that everybody else appears to be doing so.
Anybody who actually作品knows that the most productive-seeming people are often also the most-useless, as they’re doing things to似乎productive rather than producing anything of note.A great example of this is a recent Business Insider interview with a person who got laid off from Amazon after learning “AI†and “vibe coding,†and how surprised they were that these supposed skills didn’t make them safer from layoffs: At the time of the October layoffs, there was debate around whether AI was the reason.The company was encouraging us to use AI at the time, but I don't think it took my job.I wrote descriptions for internal products at Amazon, and when I used AI to help, I'd need to ask it to rewrite its output without fluff words.
It didn't sound like how people talk.Despite my ethical qualms, I used AI, but, in my opinion, it was nowhere close to replacing my role.Before I was laid off, I helped build an internal site for Amazon using AI.I hadn't really coded before, but with a colleague's help, I learned how to vibe code with a lot of trial and error.
I thought using AI for this project and showcasing different skills would make me more valuable to the company, but in the end, it didn't keep me from being laid off.
To be clear, this person is a受害者。They were pressured by Amazon to take up useless skills and build useless things in an expensive and inefficient way, and ended up losing their job despite taking up tools they didn’t like under duress.Â
旁注:If you read that sentence and suggest that sheshould’ve used AI better,你是一个标记。你正在被骗了进入一个unpaid marketing job为了AI companies that actively hate you.Â
This person was, at one point, actively part of building an internal Amazon site using AI, and had to “learn to vibe code with a lot of trial and error†and the help of a colleague.Was this a good use of her time?Was this a good use of her colleague’s time?
不!In fact, across all of these goddamn AI coding hype-beast Twitter accounts and endless proclamations about the incredible power of AI agents, I can find very few accounts ofsomething happeningother than someone saying “yeah I’m more productive I guess.â€Â
I am certain that at some point in the near future a major big tech service is going to break in a way that isn’t immediately fixable as a result of thousands of people building software with AI coding tools, a problem compounded by the dual brain drain forces of裁员和一个culture that actively empowers people to look busy rather than actually produce useful things.
What else would you expect?You’re giving people a number that they can increase to seem better at their job, what do you think they’re going to do, try and be efficient?Or use these things as much as humanly possible, even if there really isn’t a reason to?
I haven’t even gotten to how昂贵all of this must be, in part because it’s hard to fully comprehend.Â
But what I do know is that big tech is setting itself up for crisis after crisis, especially when Anthropic and OpenAI stopsubsidizing their models to the tune of allowing people to spend $2500 or more on a $200-a-month subscription.Â
What happens to the people who are dependent on these models?What happens to the people who forgot how to do their jobs because they decided to let AI write all of their code?Will they even be able to do their jobs anymore?  Large Language Models are creating Silicon Valley Habsburgs — workers that are intellectually trapped at whatever point they started leaning on these models that were subsidized to the point that their bosses encouraged them to use them as much as humanly possible.
While they might be able to claw their way back into the workforce, a software engineer that’s only really used LLMs for anything longer than a few months will have to relearn the basic habits of their job, and find that their skills were limited to whatever the last training run for whatever model they last used was. I’m sure there are software engineers using these models ethically, who read all the code, who have complete industry over it and use it as a means of handling very specific units of work that they have complete industry over.I’m also sure that there are some that are just asking it to do stuff, glancing at the code and shipping it.It’s impossible to measure how many of each camp there are, but hearing Spotify’s CEO say that its top developers are basically not writing code anymore makes me deeply worried, because this shit isn’t replacing software engineering at all — it’s mindlessly removing friction and putting the burden of “good†or “right†on a user that it’s intentionally gassing up.Ultimately, this entire era is a test of a person’s ability to understand and appreciate friction. Friction can be a very good thing.When I don’t understand something, I make an effort to do so, and the moment it clicks is magical.
In the last three years I’ve had to teach myself a great deal about finance, accountancy, and the greater technology industry, and there have been so many moments where I’ve walked away from the page frustrated, stewed in self-doubt that I’d never understand something.
I also have the luxury of time, and sadly, many software engineers face increasingly-deranged deadlines set by bosses that don’t understand a single fucking thing, let alone what LLMs are capable of or what responsible software engineering is.
The push from above to use these models because they can “write code faster than a human†is a disastrous conflation of “fast†and “good,†all because of flimsy myths peddled by venture capitalists and the media about “LLMs being able to write all code.†Generative code is a digital ecological disaster, one that will take years to repair thanks to company remits to write as much code as fast as possible. Every single person responsible must be held accountable, especially for the calamities to come as lazily-managed software companies see the consequences of building their software on sand. In the end, everything about AI is built on lies. Hundreds of gigawatts of data centers in development equate to 5GW of actual data centers in construction. Hundreds of billions of dollars of GPU sales are mostly sitting waiting for somewhere to go.
Anthropic’s constant flow of “annualized†revenues ended up equating to literally $5 billion in revenue in four years , on $25 billion or more in salaries and compute.
Despite all of those data centers supposedly being built, nobody appears to be making a profit on renting out AI compute.
AI’s supposed ability to “write all code†really means that every major software company is filling their codebases with slop while massively increasing their operating expenses.
Software engineers aren’t being replaced — they’re being laid off because the software that’s meant to replace them is too expensive, while in practice not replacing anybody at all.
Looking even an
英寸
beneath the surface of this industry makes it blatantly obvious that we’re witnessing one of the greatest corporate failures in history.
The smug, condescending army of AI boosters exists to make you look away from the harsh truth — AI makes very little revenue, lacks tangible productivity benefits, and seems to, at scale, actively harm the productivity and efficacy of the workers that are being forced to use it.Every executive forcing their workers to use AI is a ghoul and a dullard, one that doesn’t understand what actual work looks like, likely because they’re a lazy, self-involved prick. Every person I talk to at a big tech firm is depressed, nagged endlessly to “get on board with AI,†to ship more, to do more, all without any real definition of what “more†means or what it contributes to the greater whole, all while constantly worrying about being laid off thanks to the truly noxious cultures that are growing around these services.AI is actively poisonous to the future of the tech industry.
It’s expensive, unproductive, actively damaging to the learning and efficacy of its users, depriving them of the opportunities to learn and grow, stunting them to the point that they know
少
并做少because all they do is prompt.
Those that celebrate it are ignorant or craven, captured or crooked, or desperate to be the person to herald the next era, even if that era sucks, even if that era is inherently illogical, even if that era is fucking impossible when you think about it for more than two seconds.
And in the end, AI is a test of your introspection.
Can you tell when you truly understand something?你能告诉吗为什么you believe in something, other than that somebody told you you should, or made you feel bad for believing otherwise?Do you actually想要
to know stuff, or just have the ability to call up information when necessary? How much joy do you get out of becoming a better person?If you can’t answer that question with certainty, maybe you should just use an LLM, as you don’t really give a shit about anything.And in the end, you’re exactly the mark built for an AI industry that can’t sell itself without spinning lies about what it can (or theoretically could) do. want to know stuff, or just have the ability to call up information when necessary?Â
How much joy do you get out of becoming a better person?If you can’t answer that question with certainty, maybe you should just use an LLM, as you don’t really give a shit about anything.
And in the end, you’re exactly the mark built for an AI industry that can’t sell itself without spinning lies about what it can (or theoretically could) do.Â