
Meta 让承包商扮青少年测试竞品 AI,安全测试和脏活之间只隔一层外包
据 Yahoo News 援引 Wired 报道,Meta 曾通过承包商 Covalen 运行一个内部代号为 Cannes 的项目,让数百名承包商假扮青少年,使用一次性未成年人账号向 ChatGPT、Gemini 和 Character.AI 等竞品模型发送大量极端提示,试图测试这些模型的安全护栏。
 韩启明
韩启明
据 Yahoo News 援引 Wired 报道,Meta 曾通过承包商 Covalen 运行一个内部代号为 Cannes 的项目,让数百名承包商假扮青少年,使用一次性未成年人账号向 ChatGPT、Gemini 和 Character.AI 等竞品模型发送大量极端提示,试图测试这些模型的安全护栏。
一句话结论:AI 安全测试本身是必要的,但当测试对象是竞品、账号伪装成未成年人、提示内容高度刺激、结果又不公开时,它就从“安全评估”滑进了一个很灰的地带。
报道提到,一个包含近 3800 条提示的表格中,有大量内容围绕自伤、进食障碍、性相关和暴力场景,并且都以儿童或青少年的视角写成。另一次测试规模更大,涉及超过 4.5 万条提示。承包商需要把模型回应记录进表格,但 Meta 最后如何使用这些数据,并不清楚。
Meta 对 Wired 表示,这属于行业标准的安全基准测试。这个说法有一半是对的:红队测试、越狱测试、压力测试,确实是 AI 安全里必不可少的工作。问题在另一半:如果你秘密使用伪装账号去测试竞争对手产品,并把大量心理负担转嫁给外包人员,这就不再只是技术方法,而是治理问题。
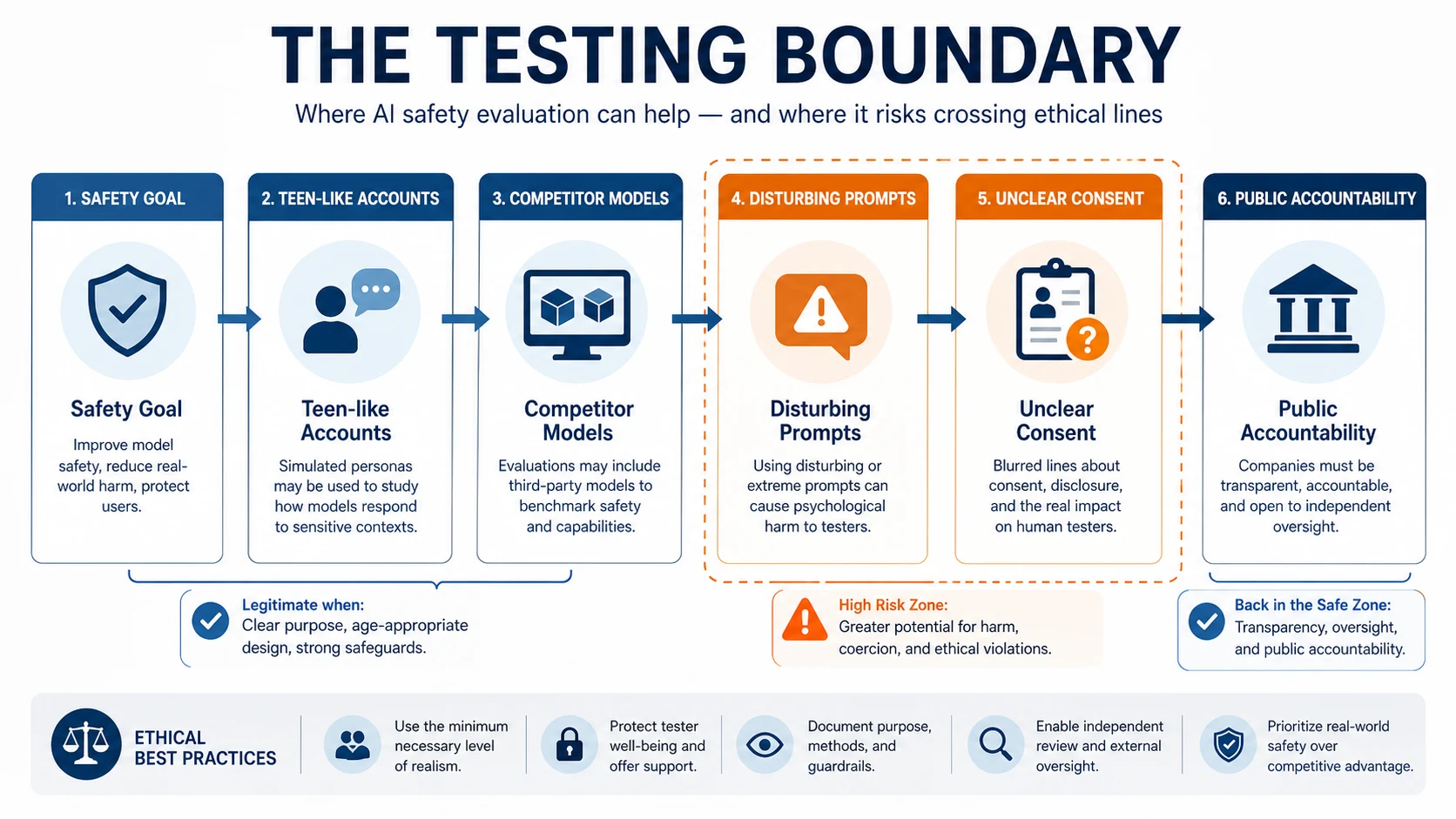
OC 的判断是,这件事最重要的不是那些猎奇提示词,而是三个边界。第一,竞品测试的边界:企业当然会研究对手,但安全测试如果以规避规则、伪装身份为前提,就很难再说只是正常评估。第二,未成年人语境的边界:用“孩子视角”批量生成高风险场景,会放大模型厂商、平台和测试人员的伦理责任。第三,外包劳动的边界:把最脏、最伤人的内容审查工作交给承包商,已经是 Meta 历史上反复出现的问题。
对普通用户来说,这条新闻也解释了一个看不见的事实:所谓“AI 安全”,背后不是只有论文、模型卡和漂亮仪表盘,还有大量人工测试、标注、筛选和精神负担。我们看到的是模型拒答一句危险请求,背后可能是很多人看过、写过、整理过成千上万条让人不舒服的材料。
对开发者和产品团队来说,真正的行业标准应该包括透明度。比如测试范围是什么,是否告知被测平台,是否经过伦理审查,是否保护承包商心理健康,是否把发现的问题负责任地披露给相关方。如果这些都没有,只剩一句“我们是在做安全”,这个理由太好用了,几乎什么都能装进去。
这件事也提醒监管者,AI 安全不是只有模型公司对用户的责任,还包括平台之间怎么测试、怎么竞争、怎么处理未成年人相关内容。今天一个大公司可以假扮青少年去打竞品模型,明天另一个公司也可以用“安全研究”之名做同样的事。行业如果不把边界讲清楚,安全测试会变成一门没有外部监督的暗活。
所以,Meta 这个项目即使目标是发现风险,也不能只用目标来洗掉过程。AI 安全当然要做,但安全不能只在发布会上体面,在后台就外包成谁都不愿意看的脏活。
参考来源




评论
围绕这篇文章补充信息、提出问题或分享观察。