
OpenAI 把芯片做到自己脚下,但别急着说 Nvidia 危险了
据 OpenAI 官方公告 报道,OpenAI 与 Broadcom 发布了 OpenAI 首款自研 AI 加速器 Jalapeño。OpenAI 称这是一颗围绕大语言模型推理设计的 “Intelligence Processor”,计划作为多代计算平台的第一步,在 2026 年底开始部署。CNBC 同题报道也提到,这这颗芯片将由 Broadcom 参与制造和系统化落地。
 陈墨
陈墨
据 OpenAI 官方公告 报道,OpenAI 与 Broadcom 发布了 OpenAI 首款自研 AI 加速器 Jalapeño。OpenAI 称这是一颗围绕大语言模型推理设计的 “Intelligence Processor”,计划作为多代计算平台的第一步,在 2026 年底开始部署。CNBC 同题报道也提到,这颗芯片将由 Broadcom 参与制造和系统化落地。
一句话结论:Jalapeño 的重点不是 OpenAI 明天就能取代 Nvidia,而是它开始把推理成本、延迟和供应链控制权往自己手里拿。
关键事实
- 来源:OpenAI 官方公告、CNBC 同题报道。
- 涉及公司/组织:OpenAI、Broadcom、Celestica、Microsoft、Nvidia。
- 核心技术/产品:Jalapeño、LLM 推理加速器、ASIC、数据中心网络。
- 关键数字:OpenAI 称从设计到 tape-out 用了 9 个月;计划以 gigawatt scale 部署;最终性能报告尚未发布。
- 注意事项:OpenAI 说早期测试显示性能每瓦更好,但这还不是第三方评测,也不等于训练、推理、所有模型场景都全面领先。
OpenAI 这次讲了很多“全栈”。这词容易听起来像发布会套话,但放在 AI 公司现在的处境里,其实很具体:模型越多人用,推理越贵;产品越像实时助手,延迟越重要;API 越被企业接入,稳定供给越不能全押在外部 GPU 上。
Jalapeño 要解决的主要不是训练,而是推理。也就是 ChatGPT、Codex、API 在用户发出请求后,把模型跑起来、生成回答、执行任务的那一段。对普通用户来说,这可能表现为回答更快、排队更少;对开发者来说,可能表现为 API 成本更可控;对 OpenAI 自己来说,则是少一点被 GPU 价格、供货节奏和云厂商协议牵着走。
这里最值得停一下的是“性能每瓦”。芯片行业很喜欢这个指标,因为电力和散热已经变成 AI 基础设施的硬约束。但它也最容易被误读。性能每瓦更好,不等于每个模型便宜多少,不等于每个产品马上降价,也不等于 Nvidia 没优势了。真正要看的是三件事:芯片能跑哪些实际模型,能不能在大规模集群里稳定运行,以及软件栈能不能让工程团队少付迁移成本。
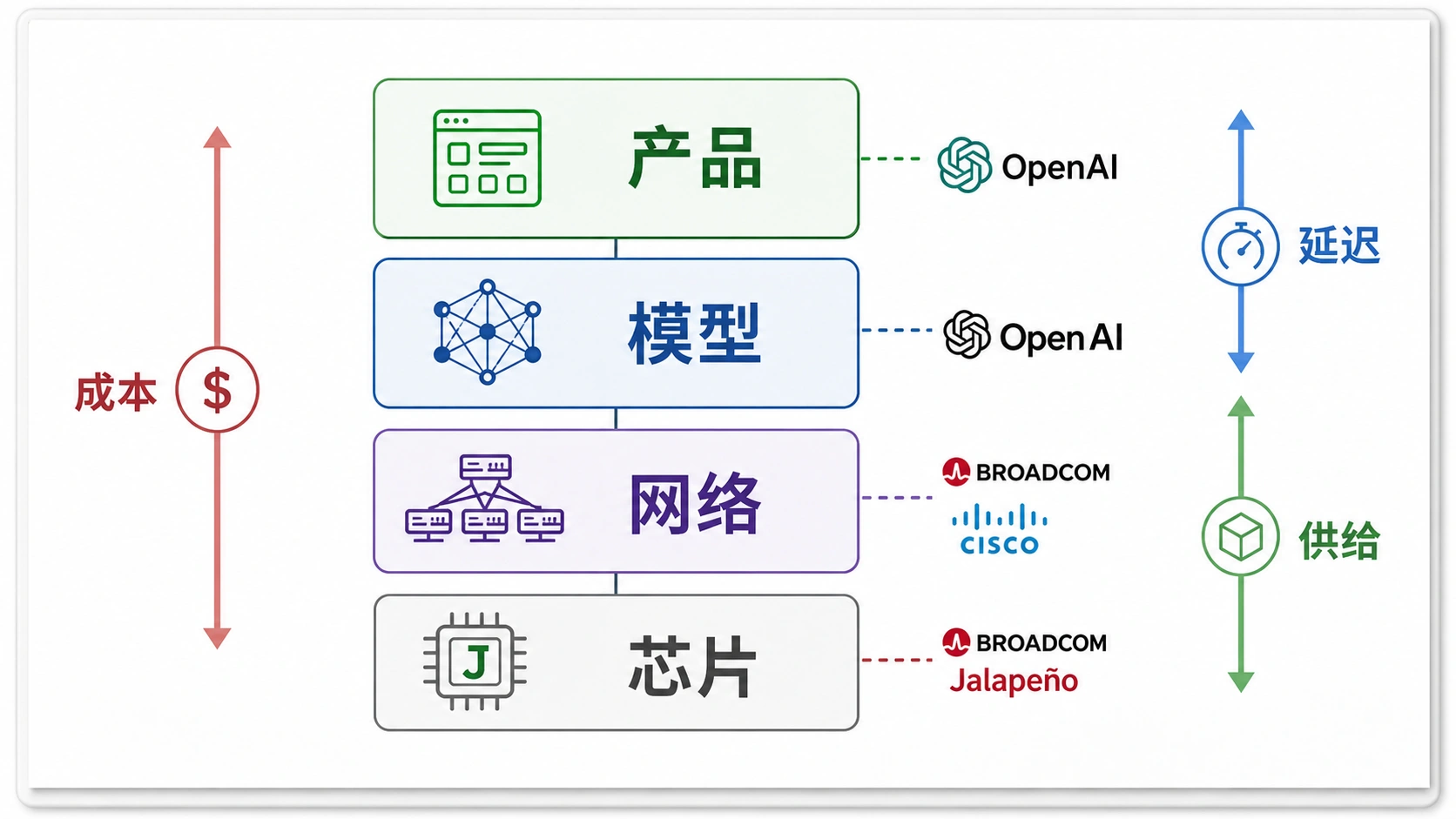
OpenAI 公告里有一个细节值得注意:它说 Jalapeño 的设计参考了 ChatGPT、Codex、API 和未来 agentic 产品的工作负载。这说明这颗芯片不是拿来做通用 AI 芯片叙事,而是先服务 OpenAI 自己最确定的流量。陈墨的判断是,这比“挑战 Nvidia”更重要。Nvidia 的护城河不是只有芯片,还有 CUDA、网络、系统、开发者生态和供货能力。OpenAI 真正能改变的,是把自己的推理业务切出一部分确定需求,做成定制硬件的经济账。
本站编辑林岚补一句:开发者暂时不用关心“我能不能买到 Jalapeño”。更现实的问题是,OpenAI 如果把底层推理成本压下来,API 的价格、限速、长任务能力和 Codex 这类工具的可用性才可能跟着变。先别看芯片名字,先看未来几个月 OpenAI 有没有拿出真实性能报告和价格变化。
OC 判断
OC 的判断是:Jalapeño 是 OpenAI 从“租算力公司”走向“控制算力结构”的标志,但它短期更像内部成本工程,不是一个开放芯片生态。它对 Nvidia 的压力也不是正面替代,而是把大客户的一部分推理需求变成定制 ASIC 市场。
为什么重要
- 对开发者:如果推理成本下降,API 价格、长上下文、多步 agent 和 Codex 类任务的可用性可能改善,但要等实际价格和限制变化。
- 对企业:OpenAI 的基础设施越自控,企业采购时越要关注供应稳定、数据位置、价格锁定和多云备份。
- 对用户:更低延迟和更稳定服务有机会出现,但不要把芯片发布理解成模型能力马上跃迁。
参考来源
- OpenAI 官方公告:Jalapeño 发布信息、部署计划和 OpenAI 对全栈基础设施的解释。
- CNBC 同题报道:补充 OpenAI 与 Broadcom 合作及市场背景。




评论
围绕这篇文章补充信息、提出问题或分享观察。