1600 名员工反对后,Meta 暂停员工追踪 AI 项目,企业里的 AI 训练边界到底在哪里?
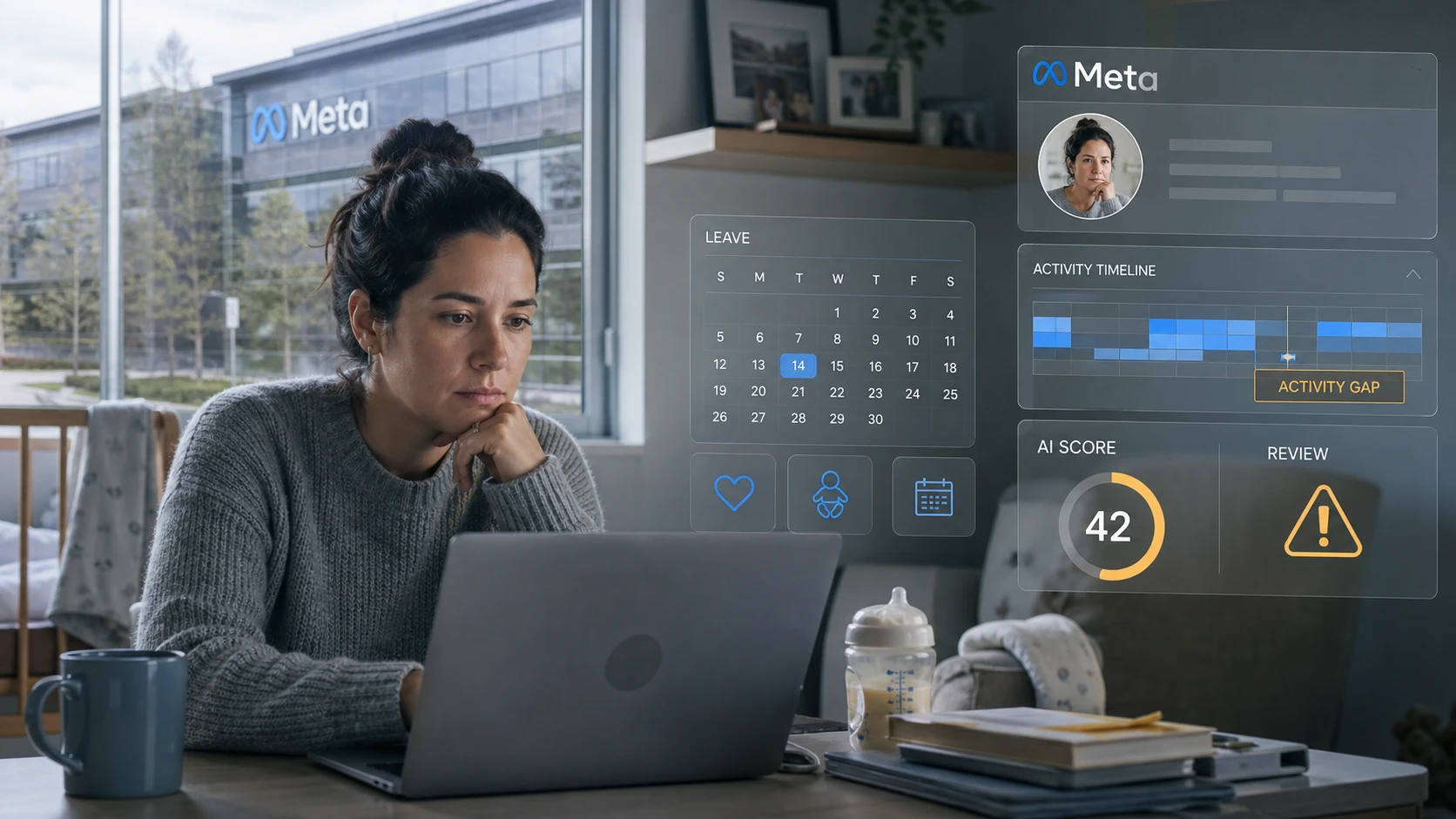
据 The Guardian 报道,Meta 暂停了一个追踪员工电脑活动以训练 AI 模型的项目。该项目名为 Model Capability Initiative,据称会记录键盘、鼠标点击和屏幕内容;超过 1600 名员工签署请愿书,反对公司收集员工“computer use”数据。
 沈南乔
沈南乔
据 The Guardian 报道,Meta 暂停了一个追踪员工电脑活动以训练 AI 模型的项目。该项目名为 Model Capability Initiative,据称会记录键盘、鼠标点击和屏幕内容;超过 1600 名员工签署请愿书,反对公司收集员工“computer use”数据。
一句话结论:Meta 这次被迫暂停的不是一个内部工具,而是企业把员工日常操作变成 AI 训练材料时必须面对的边界问题。
关键事实
- 来源:The Guardian 报道,相关内部安全问题最早由 Wired 报道。
- 涉及公司/组织:Meta、Facebook、Instagram、WhatsApp、内部员工。
- 核心技术/产品:Model Capability Initiative、computer use data、AI 训练数据。
- 关键数字:报道提到超过 1600 名员工签署请愿;Meta 2026 年 AI 资本开支规模可达 1450 亿美元。
- 注意事项:Meta 称没有证据显示数据被滥用,但项目已暂停调查;争议焦点在隐私、同意、访问权限和工作场所信任。
这条新闻和 Google Gemini 的 computer use 放在一起看,很有意思。一个是模型学会操作电脑,一个是公司想收集员工如何操作电脑的数据。二者指向同一个趋势:未来 AI 不只学文本和代码,还要学人怎样在真实软件环境里完成工作。
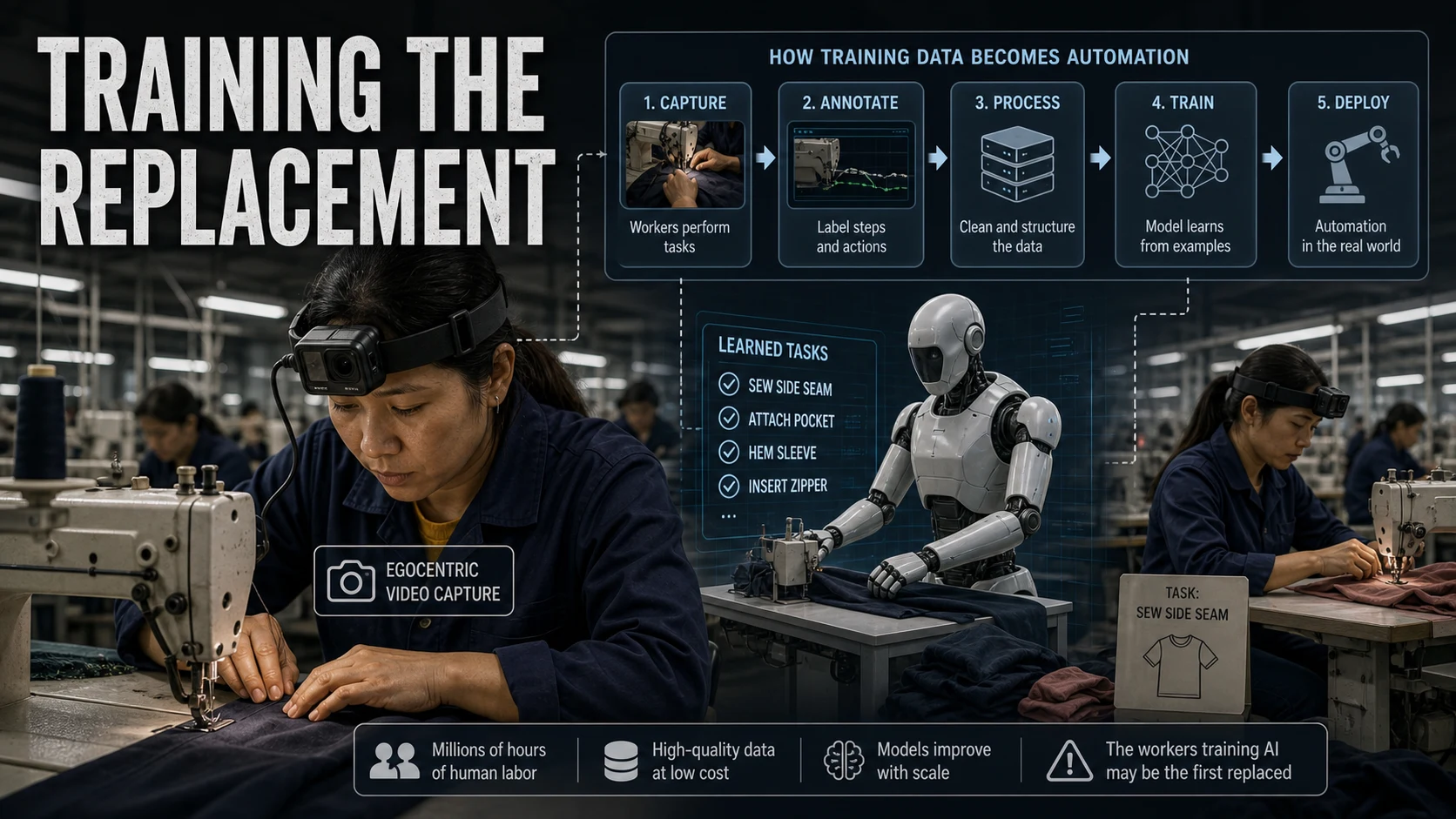
今天 OC 也报道了印度工人佩戴摄像头训练机器人的案例。一个发生在制造业,一个发生在 Meta 这样的科技公司,但底层问题相似:人的工作过程正在被转化为 AI 训练数据。值得我们关注的是采集人的工作数据是一回事;如果这些数据最终被用来训练替代他们的系统,那就是另一回事了。讽刺也正在这里:AI 自动化常常先从学习被替代者开始。
企业当然会觉得这很诱人。高级工程师怎么排查 bug,产品经理怎么整理需求,运营人员怎么在后台系统里处理异常,这些都是高价值工作流。如果能让模型学到这些流程,自动化空间会很大。
![]()
但员工不是公开网页。电脑屏幕里可能有内部战略、客户信息、同事聊天、绩效讨论、私人内容和安全凭据。即使公司拥有设备,也不等于可以无限制把员工操作转成训练数据。更麻烦的是,一旦数据被用于训练,删除、追踪和限制用途都会变得复杂。
沈南乔的判断是,这件事真正刺痛员工的不是“公司看到了我点鼠标”,而是公司把工作过程当成了可提取资源。员工贡献的不只是产出,还有如何产出的方法。如果这些方法被训练成模型,未来可能反过来用于替代、考核或压缩岗位。
OC 判断
OC 的判断是:企业 AI 训练会从“用文档和代码”走向“用员工行为”。这需要比传统 IT 监控更严格的规则:可见范围、用途限制、访问权限、删除机制、人工确认和员工退出权都应该写清楚。
为什么重要
- 对开发者:企业内部 agent 的训练数据不能随便抓,代码、屏幕和操作日志都可能包含敏感信息。
- 对企业:想用员工数据训练 AI,就必须先解决同意、隔离、访问和审计,否则信任成本会很高。
- 对用户:如果员工操作数据被模型吸收,未来产品里的自动化能力可能来自看不见的工作场所监控。
参考来源
- The Guardian 报道:原始报道,介绍 Meta 暂停员工追踪项目。
- Times of India 补充报道:补充内部数据暴露和员工反弹背景。


评论
围绕这篇文章补充信息、提出问题或分享观察。