
- 简短交流
- 开放获取
- 发表:
- 安东·阿利亚金1,4,5,
- 姆里加尤·戈什� 奥西德:orcid.org/0009-0001-2310-34116,7,
- 阿里·哈格8,
- 肖恩·尼弗特1,
- 科迪莉亚·奥瑞拉克1,
- 纳塔尼尔·J·曼德尔伯格1,
- 哈马德·汗1,
- 金维维安·李� 奥西德:orcid.org/0000-0002-8961-01251,4,5,姚杰9,
- 威廉·罗伯特·斯莫尔� 奥西德:
- orcid.org/0009-0007-3105-649510,11,12,阿卡什·瓦尔玛13,14,
- D·布洛克·休伊特15,因达隆阿芬亚纳蓬斯�
- 奥西德:orcid.org/0000-0001-8605-539210,
- 12,16,丹尼尔·亚历山大·阿尔伯� 奥西德:orcid.org/0000-0001-7957-517011&
- ���埃里克·卡尔·奥尔曼� 奥西德:orcid.org/0000-0002-1876-59631,5
- ,
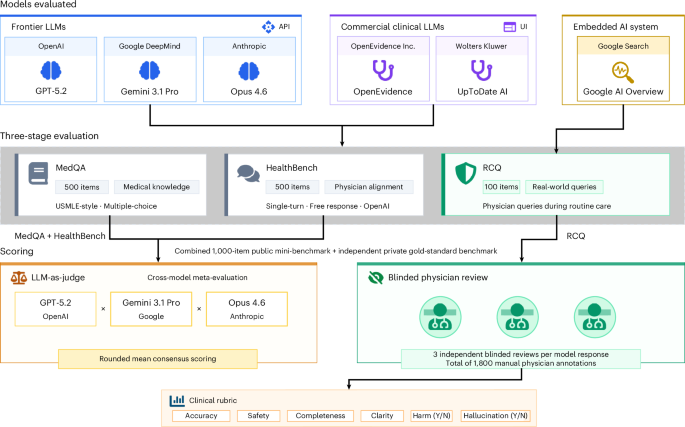
- 17 号,18,19� 自然医学(2026年)引用这篇文章摘要尽管缺乏独立评估,专业的临床人工智能(AI)工具正在进入医疗实践。我们对两种临床人工智能工具 OpenEvidence 和 UpToDate Expert AI 进行了定量评估,它们基于大型语言模型 (LLM),并针对三个前沿 LLM:GPT-5.2、Gemini 3.1 Pro 和 Claude Opus 4.6。
我们的评估分为三个阶段:(1) 500 个 MedQA 问题测试医学知识,(2) 500 个 HealthBench 项目衡量与临床医生的一致性,以及 (3) 真实临床查询 (RCQ) 基准,该基准由来自医生的 100 个去识别化查询构建,并构建于实时临床环境中的通用语言模型。对于 RCQ 基准,12 名美国临床医生对模型输出进行了随机、盲审,生成了 1,800 个模型问题注释。前沿法学硕士在所有三项评估中均优于临床人工智能工具。临床 AI 工具的表现与 RCQ 上自动启用的 Google 搜索 AI 概述相当。这些发现强调了在人工智能工具进入临床环境之前对其进行独立、真实的评估的必要性。
主要
专业临床人工智能 (AI) 工具正在大规模进入医疗实践1,2。
由于特定领域的训练或检索增强生成 (RAG),这些专有的基于大语言模型 (LLM) 的工具有望比通用前沿 LLM 提供卓越的临床表现
3。然而,他们的架构、基础模型和训练管道并不公开。因此,临床医生和卫生系统必须在没有独立证据的情况下评估其价值和安全性。相反,大型培训语料库和前沿法学硕士的广泛联合可能使他们能够挑战临床人工智能工具,而无需进行特定领域的修改。我们通过比较临床人工智能工具(OpenEvidence1和最新的专家人工智能2)到领先的通用法学硕士(OpenAI GPT-5.2、Google Gemini 3.1 Pro Preview 和 Anthropic Claude Opus 4.6)。后来,我们将自动启用的 Google 搜索 AI 概述作为医生经常遇到的现实世界控件。
我们的评价(图二)1)分三个阶段:(1)500美国医师执照考试式MedQA4评估医学知识的问题,(2) 500 HealthBench5评估与专家临床医生的一致性的项目,以及 (3) 100 个真实临床查询 (RCQ),这些查询来自现场临床部署期间医师 LLM 查询。RCQ 阶段由 12 名美国临床医生进行了随机、盲法审查,产生了 1,800 个模型问题注释。综合分析涵盖多项选择推理、专家临床判断和临床医生的日常使用。

通用法学硕士在 MedQA 问题上的表现优于临床人工智能工具(图 1)。2a和扩展数据图1a,b)。在前沿法学硕士中,Gemini 的准确率最高,为 97.4%(95% 置信区间 (CI) 95.6%–98.5%),其次是 GPT,为 94.2%(91.8%–95.9%),Claude 为 90.2%(87.3%–92.5%)。临床工具得分较低,OpenEvidence 的准确度为 89.6% (86.6%–92.0%),UpToDate 的准确度为 88.4% (85.3%–90.9%)。Gemini 的表现优于所有其他模型(McNemar磷≤<≤1≤≤10Ø4与 OpenEvidence、UpToDate 和 Claude 相比;磷相对于 GPT = = 0.02)。GPT 的表现优于 OpenEvidence(磷–= –0.008), UpToDate (磷�=�0.0004) 和克劳德 (磷≤=≤0.04)。图 2:人工智能系统在基准性能和实际临床使用方面的比较评估。该图像的替代文本可能是使用人工智能生成的。

, MedQA 准确率 (n
–= –每个模型 500 个问题)。乙, HealthBench 得分 (n–= –每个模型 500 个问题)。c, RCQ 平均临床医生评分(1-4 分制)。每一个n�=�所有 6 个模型回答了 100 个临床问题,并由 12 名临床医生中的 3 名独立评分;排除了 32 个被识别为拒绝的问题模型对,得到n每个模型有 98 (Gemini)、97 (GPT-5.2)、99 (Claude)、99 (OpenEvidence)、81 (UpToDate) 和 94 (Google AI) 非拒绝项。d, RCQ 分数按评估维度分类;样本大小如下c。e, 拒绝率 (n–= –每个模型 100 个问题)。f,克, 标记为有害内容的比例 (f)或多数票产生幻觉(3 名评分者中的 2 名)(克);样本大小如下c。观察单位是个体问题(一个,乙,e)或问题模型评估者评估(c,d,f,克);每个问题代表一个独立的观察结果,各个评估者充当独立的评估者(生物复制)。没有使用技术重复。由于该研究对所有模型进行了相互比较,因此没有指定对照组。在一个—d,数据表示为平均值±±95% CI(威尔逊评分区间一个;平均值±1.96±s.e.m.在乙—d)。斜体字母表示紧凑字母显示 (CLD) 重要性组。共享一个字母的模型没有显着差异(调整后磷> 0.05)。CLD 组源自两侧成对 McNemar 检验以及 HolmâBonferroni 校正一个,两侧 Wilcoxon 符号秩检验与 HolmâBonferroni 校正乙以及弗里德曼测试之后的双边 Nemenyi 事后测试(Ï2、= 93.65,d.f. = 5,磷≤=≤1.15≤≤10~18) 在c。值越高表示性能越好一个—d;较低的值表示更好的性能e—克。健康测试台(图二)
2b)由法学硕士评委小组进行评分,以减少单一模型偏差。分数反映了达到的评分标准分数的比例,范围为 0-100。GPT 得分最高,为 88.0 (95% CI 85.9–90.1),其次是 Gemini,为 79.3 (76.6–81.9),Claude 为 77.0 (74.2–79.9);两种临床工具得分较低(OpenEvidence 得分 62.6 (59.3–65.9) 和 UpToDate 得分 61.3 (58.0–64.6))。GPT 优于所有其他模型 (Wilcoxon磷≤<≤10Ø9),并且两种临床工具没有差异(磷≤=≤0.6)。在主题级分析中(扩展数据图 1)1c,d),GPT 在所有七个类别中排名第一或并列第一,而 OpenEvidence 和 UpToDate 在所有七个类别中排名最低或并列最低,其中六个类别与 GPT 的差异显着(磷≤0.004;例外:在不确定性下做出反应,磷≤=≤1.00)。
为了开发 RCQ 基准,我们对 NYU Langone Health Insurance Portability and Accountability Act 兼容的 GPT 实例抽取了 100 个匿名临床医生查询。12 名盲法临床医生以 1-4 分制的方式对四个维度(临床正确性、完整性、安全性/伤害避免和清晰度)的 6 个模型的反应进行评分(扩展数据图 1)。2)。对于每个回答,随机分配三名评估者进行评估。我们将 Google Search AI 概述纳入 RCQ 评估中,因为临床医生经常遇到这种情况。排除 32 条拒绝后,剩下 568 条回复。
这六个模型差异显着(弗里德曼磷≤<≤10Ø9),出现了两个性能层(图 1)。2c)。前沿法学硕士排名第一:Gemini(平均总分 3.62;95% CI 3.56–3.68)、GPT(3.54;3.47–3.61)和 Claude(3.52;3.44–3.59),他们之间没有显着差异。临床工具和 Google AI 概述紧随其后:OpenEvidence (3.24; 3.17–3.32)、UpToDate AI (3.17; 3.09–3.25) 和 Google AI 概述 (3.27; 3.18–3.35),也没有显着差异。所有九个显着的成对比较均在各层之间进行(排名双列r–= –0.5 –0.9),这意味着前沿模型在大多数个别问题上都优于临床工具,而不仅仅是平均水平。根据评级者的宽大程度进行调整后,临床人工智能工具(包括 Google AI)获得较高评级的几率比 Gemini 低 49-87%(优势比 0.13-0.51;所有磷–< –0.0001)。在灵敏度线性混合模型中,这相当于 1 – 4 分制中低 0.36 – 0.44 分(所有磷–< –0.0001)。Google AI Overview 在所有维度上的得分与 OpenEvidence 和 UpToDate AI 一样甚至更好(扩展数据图 1)。3)。
层级结构涵盖所有四个维度(图 1)。2d)。模型在清晰度方面差异最大(Kendallâs瓦�=�0.292) 且临床正确性最少 (瓦≤=≤0.141)。OpenEvidence 在清晰度方面得分最低(平均 2.84),表明其弱点在于沟通,而不是知识。定性地讲,不完整的临床内容、安全关键的遗漏和杂乱的反应很常见,特别是对于 OpenEvidence 和 Google AI 概述(扩展数据表)1)。UpToDate AI 拒绝了 19% 的查询(图 1)。2e),超过所有其他型号(1-3%;磷–< –0.01) 除了 Google AI 概述 (6%;磷≤=≤0.10)。安全结果(图二)2f,g)在不同模型之间没有差异:没有一个模型产生更多有害内容(Cochran’s问≤=≤4.00,磷≤=≤0.55) 或幻觉 (问≤=≤5.00,磷–= –0.42) 比其他任何一个都高。所有 12 名临床医生对模型的排名都相似(Kendall 的瓦≤=≤0.651,磷≤=≤2.3≤≤10Ø7),将前沿法学硕士置于临床工具之上(扩展数据图 1)。4)。
这项研究使用现实世界的医生在护理过程中的查询,对临床人工智能工具与前沿法学硕士进行了独立、定量的比较。临床人工智能工具在每项评估中都落后于前沿模型:知识、专家协调和跨多个维度的实际临床使用。Google AI Overview 是一项自动搜索功能,在该基准测试中与临床 AI 工具相匹配。
由于专有临床人工智能工具的架构无法访问,因此无法明确评估其相对于通用模型表现不佳的机制理解。有证据表明,RAG 很可能被 OpenEvidence 所采用1和最新的专家人工智能2,当基本模型检索到不相关材料或集成不良时,实际上可能会对模型性能产生负面影响6,7,8。前沿法学硕士可能只是更擅长大多数医学问题的知识检索和推理9。与专业系统相比,它们还受益于更快的迭代周期、更大的培训语料库和更好的一致性。前沿通用模型的观察到的优势可能反映了这些系统的加速开发和投资。如果规模化回报减少,特定领域的调整、策划检索和临床医生循环优化的相对价值可能会增加。因此,我们的结果应该被解释为快速发展的景观的快照,而不是方法的永久排序。特别是,深度细分的医疗任务可能有利于更复杂的、特定领域的适应9,10,11。
这项研究有几个局限性。临床工具缺乏公共应用程序编程接口(API),因此需要通过浏览器接口进行查询,这限制了样本大小,并且可能会在隐藏提示、检索行为和输出格式方面引入差异。标准化基准存在数据泄露等已知问题7;模型可能在训练过程中接触过 MedQA 或 HealthBench,但我们的 RCQ 基准没有受到这种污染。HealthBench 是 OpenAI 开发的基准测试,每个评分标准都依赖少数医生,公共文档提供的构建和评估细节有限5。OpenAI 模型(包括 HealthBench 上得分最高的模型 GPT-5.2)的评估可能会受到潜在基准与开发人员重叠的影响,包括训练数据、优化目标或标题设计方面的潜在相似性。评分偏差也是可能的,因为前沿模型既充当评估系统又充当法官,尽管我们使用多模型小组来减轻这种影响。因此,我们将临床医生对 RCQ 基准的盲法评估视为本研究的主要证据,而 HealthBench 应解释为补充证据。
更广泛地说,行业创建的基准可能会系统地有利于其创建者开发的系统,从而增强了对独立构建的评估工具的需求。RCQ 基准部分解决了这个问题:它源自真实的临床查询,由盲法临床医生进行评估,并且不受训练集污染。此外,最近提出了对法学硕士医疗建议的以安全为中心的评估,例如 NOHARM12框架表明知识和沟通基准可能无法完全捕捉临床风险。相关工作还指出以卫生系统为基础的评估框架,例如嵌入当地临床工作流程中的机构特定操作任务和预测设置,作为公共、行业制定基准的重要补充,因为它们可以更好地捕捉模型在给定护理环境中是否在临床上有用。13,14。
最后,我们的评估没有评估响应延迟或引用质量。这些因素对于现实世界的临床部署和工作流程集成非常重要,并且在 API 访问的前沿模型和基于订阅的临床工具之间可能存在很大差异(扩展数据表2)。未来的工作应该系统地比较这些实际维度以及准确性和安全性。
临床人工智能工具可能具有机构合法性,并且日常使用可能是安全的,但我们的结果表明,它们并不优于知识、沟通或临床一致性方面的前沿模型。我们研究中前沿模型的卓越性能表明,作为特定任务的医疗能力的决定因素,规模、一致性和跨领域推理可能比特定领域的调整更重要,这一发现对采购、报销和监管监督具有影响。前进的道路最终可能取决于利用机构数据的医院特定法学硕士13,14以减轻外部伤害15,以及谨慎使用前沿模型来完成不太敏感的任务16。随着生成法学硕士融入企业、个人临床医生和消费者层面的医疗保健,对现实世界任务进行严格、独立评估的需求越来越大。
方法
研究立项及标杆建设
这项研究得到了纽约大学朗格尼机构审查委员会的批准 (i23-00510)。我们从 MedQA 中随机抽取了 (seed-=-62) 500 个美国医师执照考试类型的问题4以及来自 HealthBench 的 500 个单轮提示5。这 1,000 个项目用于通过 API 评估三个前沿 LLM:GPT-5.2(2026 年 2 月访问,GPT-5.2-2025-12-11)、Gemini 3.1 Pro Preview(2026 年 2 月访问)和 Claude Opus 4.6(2026 年 2 月)。通过浏览器界面手动查询两个临床工具:OpenEvidence(2025 年 9 月和 2026 年 2 月访问)和 UpToDate Expert AI(2025 年 11 月和 2026 年 2 月访问)。
发电参数
前沿模型的生成是使用固定的、确定性的参数进行的。所有运行均启用搜索工具。温度设置为 0.0 以消除采样变异性,并使用 62 的固定代种子。尽管跨系统匹配响应长度或格式会减少变异性来源,但我们选择了这种方法,因为输出结构、详细程度和格式是每个系统临床界面的组成部分,并直接影响清晰度等维度;标准化这些特征会掩盖临床医生在实践中遇到的真正可用性差异。
MedQA 评分
GPT-4.1 (gpt-4.1-2025-04-14) 提取每个模型的最终答案,并根据参考密钥对其进行评分。正则表达式提取并行运行作为一致性检查;分歧被手动验证。霍尔马·邦费罗尼纠正道,显着性是通过精确的麦克尼马尔检验进行检验的。结果报告的准确度为 Wilson 的 95% CI。
HealthBench 评分
根据五个轴上所达到的评分标准的比例对回答进行评分:准确性、完整性、沟通质量、情境意识和指令遵循。符合的轴比例以 Wilson 的 95% CI 报告。响应还分为七个主题:紧急转诊、背景寻求、全球健康、健康数据任务、专业定制的沟通、不确定性下的响应和响应深度。评分采用三位评委的小组多数投票(Claude Opus 4.6、Gemini 3.1 Pro Preview 和 GPT-5.2);扩展数据图给出了判断提示。5(参考。5)。成对显着性通过 Wilcoxon 符号秩检验进行检验,Holm-Bonferroni 纠正了这一点。总体 HealthBench 分数和主题分数以平均分数报告,具有正常近似 95% CI。
真实的临床询问
我们从符合 NYU Langone Health Insurance Portability and Accountability Act 的 GPT 实例中抽取了 100 个去识别化的查询。每个查询都提交给六个模型:三个前沿法学硕士、两个临床工具和 Google 搜索人工智能概述。十二名临床医生评估者对模型身份不知情,使用 1-4 分制对四个维度(临床正确性、完整性、安全性/伤害避免和清晰度)的反应进行评分(扩展数据图 1)。2),带有有害内容和幻觉的二进制标志。三位评分者对每个问题——模型对进行评分;没有一个评估者能够保证对给定问题的所有六个回答(扩展数据图 1)。6)。对于统计分析,如果三位评论者中的大多数人分配了相应的标签,则将项目(模型响应 - 问题对)分类为有害或包含幻觉。
RCQ统计分析
拒绝被标记并手动验证;如果任何评分者将某个问题模型对标记为拒绝,则该对的所有评分都会被排除,从而在 568 个项目中产生 1,704 个评分(丢弃 32 个拒绝)。总分计算为四个维度的平均值,每个项目的三个评分者的平均值。
评估者间的可靠性通过 Krippendorff 的 alpha(序数)进行评估。项目级协议是公平的(α-= -0.10 - 0.20),尽管相邻分数之间存在分歧(±1 一致范围内 89% - 95%)。当折叠到可接受 (3-4) 与不可接受 (1-2) 时,一致性更高(流行率调整偏倚调整 kappa = -0.55 - 0.83)。对二元安全标志的一致性很高(针对伤害,患病率调整后偏差调整的 kappa = 0.86,对于幻觉,kappa = 0.95)。
我们将配对比较限制为 74 个完整问题,其中所有六个模型均未拒绝(完整案例偏差:最大差异 0.034 分)。弗里德曼检验评估了总体差异;Nemenyi 事后测试识别了不同的配对,同时控制了家族误差。Wilcoxon 符号秩检验与 Holm-Bonferroni 修正成对提供磷价值观。效应大小通过秩双序列相关性进行量化(来自 5,000 次引导迭代的 95% CI)。对所有 568 个项目进行 Kruskal-Wallis 测试作为敏感性分析;结果是一致的。
具有评估者固定效应的累积链接模型(比例赔率逻辑回归)是主要回归。具有随机评估者截距的线性混合模型用作敏感性检查。二进制标志与 Cochran 进行比较问和成对麦克尼马尔检验,霍尔马·邦费罗尼纠正道。拒绝率与费舍尔精确检验进行了比较。所有测试均在两侧进行α≤=≤0.05。
报告摘要
有关研究设计的更多信息,请参阅自然投资组合报告摘要链接到这篇文章。
数据可用性
医学质量保证 (https://huggingface.co/datasets/GBaker/MedQA-USMLE-4-options)和健康基准(https://huggingface.co/datasets/openai/healthbench)基准测试可在 HuggingFace 上公开下载。本研究中使用的特定 500 项子集可以使用中描述的随机种子 (seed-=-62) 进行重现方法。真实临床查询 (RCQ) 基准源自根据 NYU Langone IRB 协议 i23-00510 收集的去识别化临床医生查询。由于这些查询源自临床环境,因此由于机构审查和数据使用协议,RCQ 数据集不可供公众使用。
代码可用性
支持这项研究的代码可公开获取:https://github.com/nyolab/clinical-llm-benchmarks。参考文献
OpenEvidence 是历史上增长最快的医生应用程序,宣布完成 2.1 亿轮融资,估值 35 亿美元。
C美通社https://www.prnewswire.com/news-releases/openevidence-the-fastest-forming-application-for-physicians-in-history-announces-210-million-round-at-3-5-billion-valuation-302505806.html (2025)。HLTH 2025:Wolters Kluwer 展示 UpToDate Expert AI 和工作流程创新。
瓦奥尔特斯克鲁韦尔https://www.wolterskluwer.com/en/news/uptodate-expert-ai-workflow-hlth-2025 (2025)。Amugongo, L. M.、Mascheroni, P.、Brooks, S.、Doering, S. 和 Seidel, J. 医疗保健中大型语言模型的检索增强生成:系统评价。
PLOS 数字。健康 4,e0000877 (2025)。
金,D.等人。这位患者得的是什么病?来自医学检查的大规模开放域问答数据集。应用。科学。(巴塞尔) 11,6421(2021)。
阿罗拉,R.K.等人。HealthBench:评估大型语言模型以改善人类健康。预印本于https://doi.org/10.48550/arXiv.2505.08775(2025)。
Vishwanath,K.等人。医学大语言模型很容易分散注意力。预印本于https://doi.org/10.48550/arXiv.2504.01201(2025)。
Vishwanath, K.、Stryker, J.、Alyakin, A.、Alber, D. A. 和 Oermann, E. K. MedMobile:具有临床功能的移动大小的语言模型。英国医学杂志数字。健康人工智能 1,e000068 (2025)。
Wu, E.、Wu, K. 和 Zou, J. ClashEval:量化法学硕士内部先前证据和外部证据之间的拉锯战。在神经信息处理系统的进展 3733402–33422(神经信息处理系统基金会,2024 年)。
阿利亚金,A.等人。CNS-Obsidian:根据科学出版物构建的神经外科视觉语言模型。神经外科 https://doi.org/10.1227/neu.0000000000004070(2026)。
奥沙利文,J. W. 等人。用于复杂心脏病护理的大型语言模型。纳特。医学。 32,616–623 (2026)。
诺里,H.等人。使用语言模型进行顺序诊断。预印本于https://doi.org/10.48550/arXiv.2506.22405(2025)。
吴,D.等人。首先,做 NOHARM:走向临床安全的大语言模型。预印本于https://doi.org/10.48550/arXiv.2512.01241(2025)。
蒋,L.Y.等。通才基础模型对于医院运营来说还不够临床。预印本于https://doi.org/10.48550/arXiv.2511.13703(2025)。
蒋,L.Y.等。卫生系统规模的语言模型是通用预测引擎。自然 619,357–362 (2023)。
阿尔伯,D.A. 等人。医学大语言模型容易受到数据中毒攻击。纳特。医学。 31,618–626 (2025)。
马尔霍特拉,K.等人。在整个卫生系统范围内获取生成人工智能:纽约大学朗格尼健康中心的经验。J. Am.医学。通知。副教授。 32,268–274 (2025)。
致谢
我们感谢 N. Mherabi 和 D. Bar-Sagi 对纽约大学朗格尼分校医学人工智能研究的支持。我们感谢 M. Constantino 和 NYULH 高性能计算 (HPC) 团队为我们的工作提供了至关重要的计算资源。
资金
E.K.O.得到美国国家癌症研究所早期外科医生科学家计划 (3P30CA016087-41S1) 和 W.M.凯克基金会。这项工作得到了韩国政府科学和信息通信技术部 (MSIT) 资助的信息与通信技术规划与评估研究所 (IITP) 赠款的支持(编号 RS-2019-II190075 人工智能研究生院计划 (KAIST);编号 RS-2024-00509279,全球人工智能前沿实验室)。资助者在研究设计、数据收集和分析、出版决定或手稿准备中没有任何作用。
道德声明
利益竞争
E.K.O.报告了 MarchAI 和 Artisight 的股权、Eikon Therapeutics 的配偶就业以及 Sofinnova Partners 和 Google 的咨询。其余作者声明没有竞争利益。
同行评审
同行评审信息
自然医学感谢 Leo Anthony Celi 和 Stephen Gilbert 对这项工作的同行评审所做的贡献。同行评审报告可用。主要处理编辑:Mattia Andreoletti,与自然医学团队。
附加信息
出版商备注施普林格·自然对于已出版的地图和机构隶属关系中的管辖权主张保持中立。
扩展数据
扩展数据图 1 生成式 AI 模型在医学知识和临床推理基准子类别中的性能。
(一个) 按器官系统划分的 MedQA 准确性和 (乙)按五种模型(OpenEvidence、UpToDate Expert AI、GPT-5.2、Gemini 3.1 Pro、Claude Opus 4.6)的能力划分。数据以准确度 ± Wilson 的 95% CI 表示。每个系统的样本大小如下,按照从左到右的相同顺序(一个): 5, 34, 32, 31, 49, 50, 36, 41, 50, 54, 34, 35, 26, 10, 4, 7。每种能力的样本量如下,从左到右的顺序与(乙): 240, 116, 131, 4, 5, 2。(c) HealthBench 按主题得分和 (d)通过分级轴。数据以平均分数±正常近似 95% CI 的形式表示(c)和满足 ± Wilson 95% CI 的比例(d)。每个主题的样本大小如下,从左到右的顺序与(c): 81, 45, 90, 59, 80, 101, 44。每个轴的样本大小如下,从左到右的顺序与 (d): 451, 60, 214, 290, 86。在 (一个)-(d),字母表示显着的成对差异(McNemar 的检验(一个), (乙) 和 (d);和 Wilcoxon 检验 (c);P≤<≤0.05);共享一个字母的模型没有区别。
扩展数据 图 2 RCQ 临床医生评估细则。
临床医生评估人员被指示遵循与医学法学硕士查询相关的四个轴(维度)的四点评分量表。二进制标志用于关于伤害和幻觉的是/否问题。评估人员被指示记录拒绝的 1-1-1-1 分数,这些分数在从分析中删除之前经过手动确认。
扩展数据图 3 六种人工智能工具的临床医生评级的成对比较和回归模型。
(一个—d) 四个评估维度上所有成对比较的排名双列效应大小 (r) 的热图:临床正确性 (一个),完整性(乙)、安全/避免伤害(c),以及临床医生的清晰度(d)。每个单元格显示行工具与列工具的秩双列 r。效应大小源自对 n≤=≤74 个完整病例临床查询(所有六个模型都返回非拒绝响应的 100 个总查询的子集)的双边 Wilcoxon 符号秩检验,每个维度独立计算。以粗体列出的单元格表示在显着性综合 Friedman 检验之后通过双边 Nemenyi 事后检验得出的统计显着差异(通过学生化范围分布在所有 15 个成对模型比较中控制家庭明智的 α = 0.05)。(e) 具有评级者固定效应的累积链接(比例优势)模型的优势比森林图,估计每个工具相对于 Gemini 3.1(参考)获得更高顺序评级的可能性。点表示优势比点估计 (exp(β)),水平条表示四个维度中每个维度的 95% Wald 置信区间 (exp(β–±–1.96 × SE))。模型分别针对 n = = 1,704 个评估者项目观察值的每个维度进行拟合(568 个非拒绝模型 - 问题对 – 每对 3 个独立临床医生评估者;12 个独特的盲态美国临床评估者)。每个模型与参考系数的 Wald 检验都是双面且未经调整的,因为 CLM 是预先指定的主要回归。比值比低于 1.0 表示与参考值相比获得较高评级的可能性较低。(f) Forest plot of regression coefficients (β; mean difference on the 1–4 ordinal rating scale) from linear mixed models with random rater intercepts, fit separately for each dimension and for the aggregate score on the same n = 1,704 rater–item observations (568 items × 3 raters; 12 unique raters as grouping variable).Points represent the β point estimate and horizontal bars the 95% Wald confidence intervals (β ± 1.96 × SE);two-sided Wald P-values, unadjusted.Asterisks denote significance levels: *P < 0.05, **P < 0.01, ***P < 0.001.
扩展数据图 4 临床医生评分分布、头对头比较以及 RCQ 上的评分者一致性。
Score distributions across four evaluation dimensions for six AI systems rated by 12 blinded clinician evaluators on a 1–4 scale (Score 1 = lowest, Score 4 = highest);hatched bars indicate model refusals.Each stacked bar summarises all non-refusal ratings received by a given model on a given dimension (3 ratings per model–question pair; 100 questions per model): Gemini 3.1 Pro n = 294, GPT-5.2 n = 291, Claude Opus 4.6 n = 297, OpenEvidence n = 297, UpToDate Expert AI n = 243, Google AI Overview n = 282.Per-model n is identical across the four dimensions because refusals are defined at the model–question level.Brackets denote significant pairwise differences by two-sided Nemenyi post-hoc test following a significant omnibus Friedman test on n = 74 complete-case questions (family-wise α = 0.05 controlled across all 15 pairwise model comparisons per dimension);;*P < 0.05, **P < 0.01, ***P < 0.001.Bottom left: head-to-head win rate matrix showing the proportion of queries on which each row model outscored each column model on the aggregate score across n = 74 complete-case questions (ties contributed 0.5 to the row model).Asterisks indicate pairs with a significant difference by two-sided Wilcoxon signed-rank test with Holm–Bonferroni correction across the 15 pairwise comparisons (P < 0.05).Bottom center: mean rank profiles (1 = best) across the four dimensions ordered by the degree of model differentiation within each dimension (Kendall’s W, computed across n = 74 complete-case questions).Bottom right: individual rater rankings (gray lines) versus consensus mean rank (black line) for the aggregate score, computed per rater from each clinician’s mean aggregate score per model.Inter-rater concordance on model ranking was assessed with a two-sided Friedman test across the six models, from which Kendall’s W was derived (W = χ2/ [n(k − 1)];k = 6 models).Agreement was strong (W = 0.651, Friedman\({\chi }_{5}^{2}=39.05\), P = 2.3 × 10â»7;n = 12 independent clinician raters).
Extended Data Fig. 5 HealthBench grader prompt.
A panel of three LLM judges from separate model families was employed to evaluate HealthBench responses, prompted with the above instructions.
Extended Data Fig. 6 Clinical evaluation platform and sample question.
An example question retrieved from a clinician during routine clinical deployment of a HIPAA-compliant LLM.Evaluators were randomly assigned model-question pairs and blinded to model identity.Three clinicians reviewed each model-question pair.
补充资料
权利和权限
开放获取This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material.You do not have permission under this licence to share adapted material derived from this article or parts of it.The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material.If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.To view a copy of this licence, visithttp://creativecommons.org/licenses/by-nc-nd/4.0/。转载和许可
引用这篇文章

Vishwanath, K., Alyakin, A., Ghosh, M.
等人。General-purpose large language models outperform specialized clinical AI tools on medical benchmarks.Nat Med(2026)。https://doi.org/10.1038/s41591-026-04431-5
已收到:
已接受:
已发表:
记录版本:
DOI:https://doi.org/10.1038/s41591-026-04431-5